
Introduction
Large Language Models (LLMs) simulate human-like interaction by generating context-aware natural language responses. They are data-driven and generate responses based on a pre-existing reservoir of knowledge. However, this knowledge is limited. LLMs struggle with challenges like contextually plausible but factually inaccurate information, niche domain knowledge and diversity in interactions.
Retrieval Augmented Generation (RAG) can address some of these issues by allowing the LLM to tap into external sources of data, which might be factual, context-specific, domain-specific or simply more up-to-date than the data the LLM was trained on. It also betters the accuracy of the model responses, and deters it from hallucinating.
In this blog, we consider a contact center use case having customer support data. We go over setting up a RAG implementation where we add this data as context to Symbl.ai’s Nebula Chat LLM, and work with MongoDB Atlas to store this data and retrieve relevant information in response to a user query.
About Symbl.ai
Symbl.ai is striving to push forward the boundaries of conversational intelligence. It provides tools and technologies for individuals and businesses to harness the intelligence present in human interactions. Symbl’s APIs generate analytics and insights from conversation data. A few examples include sentiments, bookmarks, trackers, redaction and summary. To explore these features, sign up here.
Symbl has developed a proprietary LLM – Nebula Chat. Nebula Chat supports all forms of text data, but is optimized for raw or processed interaction data procured from channels like chat sessions, e-mails, phone/video calls etc. It is integrated with Symbl’s own embedding model – Nebula Embedding. The Nebula Embedding model, for a given text input, creates a vector representation of length 1024. These vector embeddings are used to calculate the semantic similarity between different chunks of text, using metrics like cosine similarity. This embedding model is also tailored for higher performance on human interaction data.
MongoDB Atlas
MongoDB Atlas is a cloud database solution adept at handling large-scale data, with capabilities extending to vector databases. Generating context for RAG implementations begins with creating vector embeddings using the external data to be added. Storing embeddings in a vector database is pivotal for the retrieval component, enabling the maintenance of context in conversations. As the next step, an efficient similarity search between the user query and the stored embeddings is fundamental to an accurate response. Vector databases optimize this process by efficiently retrieving pertinent documents or data points based on user queries. This data is then fed as context to the LLM which generates an augmented response.
As the volume of data grows, the scalability of the retrieval process also becomes crucial, and vector databases are designed to handle large-scale datasets while ensuring real-time responsiveness. Additionally, these databases support the execution of different retrieval strategies and complex queries.
Atlas Vector Search is a highlight of MongoDB Atlas – it leverages vector indexes to represent and query complex data structures, and also unstructured data. The robust capabilities of Atlas Vector Search stem from its unique ability to interpret and analyze data within a multidimensional space. This adaptability is particularly crucial in applications where context-aware search functionalities are paramount. Documentation on MongoDB Atlas can be found here.
Integrating Nebula Chat and MongoDB Atlas
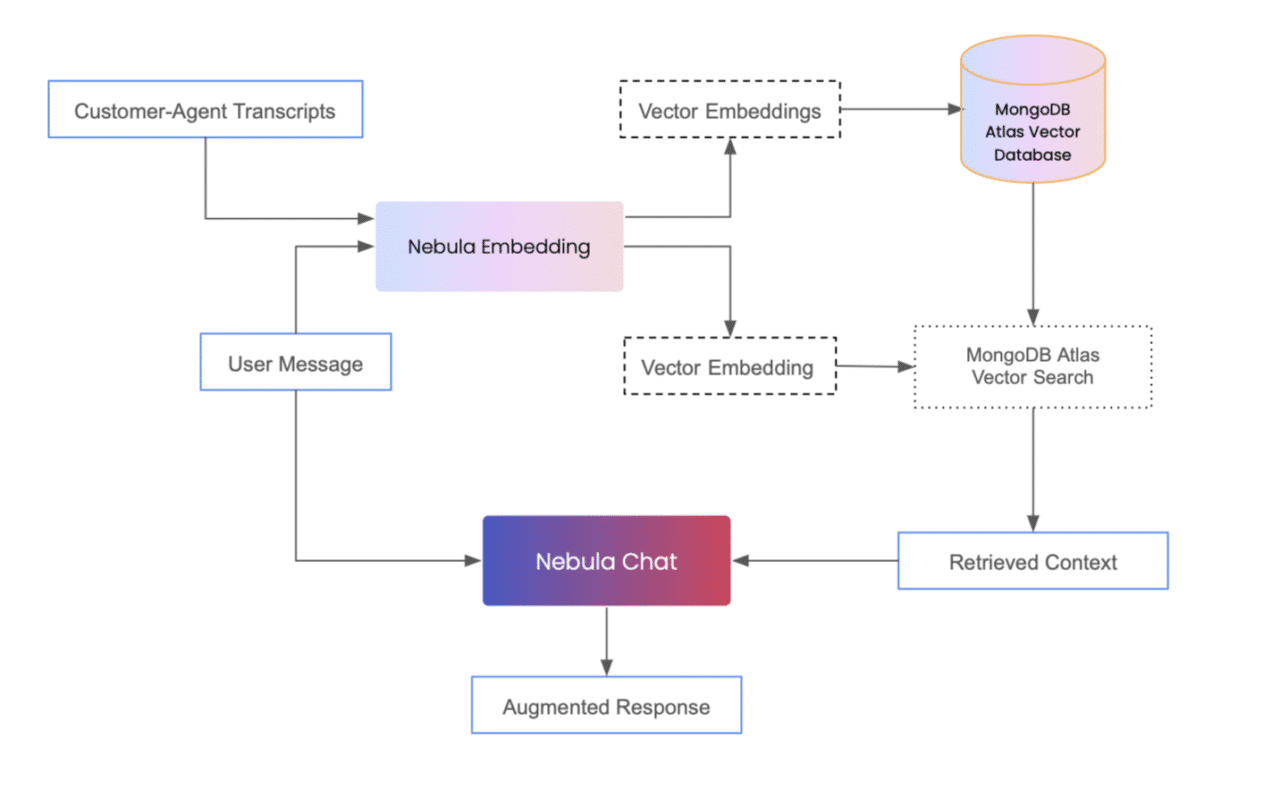
Set Up: Nebula API Key and MongoDB Client
To request a Nebula API key, sign up here.
Also set up a MongoDB Atlas account by visiting this link. Find your MongoDB URI by clicking “Connect” > “Drivers” > “Add your connection string … ”
Step 1: Import libraries
Install and import the necessary Python libraries:
- requests for making HTTP requests.
- pymongo for establishing connection with a MongoDB client.
- json for working with JSON data.
- csv for reading and writing CSV files.
- urllib for parsing through URLs.

Step 2: Set up a MongoDB connection
Establish a connection to MongoDB using the URI credentials obtained in ‘Set Up’ and specify a database (chat_transcripts) and collection (samples4) to be used. If the database and collection do not already exist, they will be created.

Step 3: Define create_embeddings function
Create a function that sends text to the Nebula Embedding model API (https://api-nebula.symbl.ai/v1/model/embed) and retrieves the embedding for the given text.


Step 4: Define insert_documents function
Create a function to read data from a file, create embeddings for each conversation transcript, and insert documents (conversation text with embeddings) into the MongoDB collection.
The dataset used for this implementation consists of CSV files, each with two columns – conversation ID and associated transcript. An embedding is generated for each conversation transcript using the create_embeddings function. This embedding along with the associated conversation_id and text transcript, make up a document, which is then inserted into MongoDB. A total of 80 documents are inserted in this implementation, spanning four CSV files, with 20 rows each.
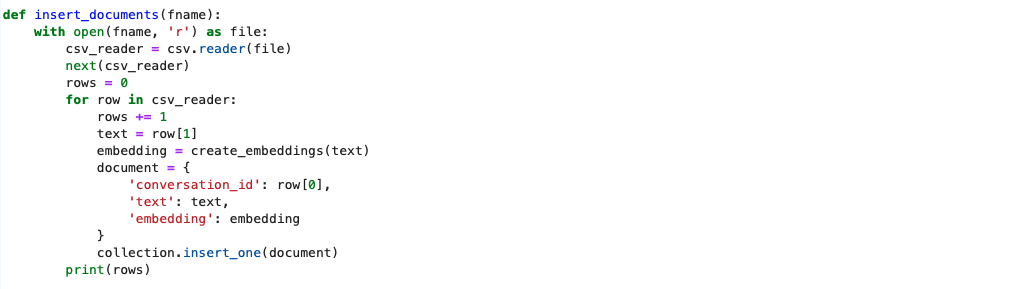
Step 5: Create a vector search index
Navigate to the database in your collection on the Atlas page and follow instructions to create an Atlas Vector Search Index. Provide an index name – this implementation uses “vector_index”, and add a JSON configuration.
- numDimensions: length of the vector embeddings
- path: field over which the similarity search is carried out
- similarity: similarity metric used

Step 6: Define vector_index_search function
Create a function to perform a vector index search in MongoDB using the vector search index created in the previous step. This function takes a user prompt as input and returns the retrieved context from the vector database.
MongoDB Atlas Vector Search uses an approximate nearest neighbors algorithm. For this implementation, our dataset includes 80 documents in total (numCandidates). We return the 7 (limit) closest documents to the user prompt as an output of this search.

Step 7: Define chataugmentation function
Create a function to interact with the Nebula Chat model API for chat augmentation based on the additional context and user query.

Step 8: Insert Data into MongoDB
Insert data from the relevant CSV files into the MongoDB collection using the insert_documents function.

Step 9: User Interaction Loop
Finally, create a loop that allows the user to input a question, perform a vector index search, add context to the LLM and print the augmented responses.

Step 10: Running the Script
Execute the script in a Python environment, ensuring that all dependencies are installed. Make sure to have the required CSV files in the same directory.
Sample Output

The script outputs conversation IDs associated with the 7 (set as limit in vector_index_search function) closest embeddings present in the database. The transcript corresponding to these conversations are added as context to Nebula LLM, which then based on the user prompt, generates an augmented response.
Conclusion
This blog demonstrates a step-by-step integration between Symbl.ai’s Nebula Chat LLM and MongoDB Atlas to develop a RAG pipeline, with the objective of drawing insights from conversation data added as context. A few use cases include question-answering, document summarization, and content generation. Low token latencies, for the Nebula Chat and Embedding models, also make this framework suitable for real-time and time-sensitive use cases in generative AI, for instance customer service, technical support and sales assistance. This synergy can further be leveraged to build more advanced and contextually aware conversational agents.