
In today’s world, the majority of resources in NLP and Generative AI – models, data, and evaluation metrics – are devoted to the English language. This poses a problem for conversational applications and models, which must adapt to the people and the populations that they will ultimately be deployed in. Additionally, the challenges of conversational and spoken language are such that straightforward machine-generated translations will not accurately capture and represent all of the linguistic nuances inherent in multi-party human conversations. In this post, we consider some of the challenges inherent in supporting multilingual processing with current language models, and some of the nuances that are specific to conversational data. We conclude by showing the abilities of our Nebula family of models from Symbl.ai to handle multilingual cases, as well as larger context windows to accommodate the natural length of human conversations.
Unity in (Lack of) Diversity
The lack of linguistic diversity in NLP starts at the very beginning of the funnel, in the engines of linguistic innovation – NLP conferences. In their seminal 2020 paper on the “The State and Fate of Linguistic Diversity and Inclusion in the NLP World”, Joshi et al. point out the linguistic diversity – or lack thereof – in the world of natural language processing, represented via the major NLP conferences. They offer a division of human languages into 6 classes, ranging from the “left-behinds” at a value 0, all the way to the “winners” at 5; and demonstrate that the distribution of data and research effort devoted to each of these languages is extremely uneven.
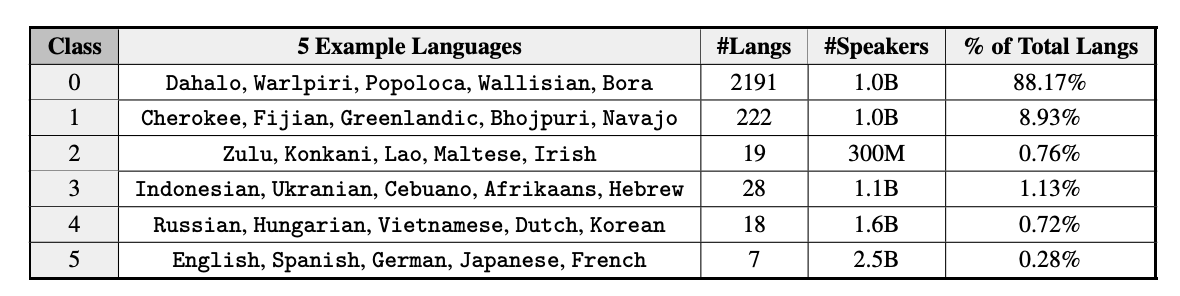
Even in 2020, prior to the hurried and hectic LLM revolution, the staggering disparity evident in the availability of data across the 6 language classes is sobering. The graphic below about different available resources for various languages is instructive, as all of the large language models in use today have been pre-trained on some snapshot of available web and other data. Such models will necessarily reproduce the representational (multi)linguistic biases of the data that they have seen.

Surveying MLLMs
To counter the effects of such skewed distributions, Doddapaneni et al. (Doddapaneni, S., Ramesh, G., Khapra, M. M., Kunchukuttan, A., & Kumar, P. (2021). A primer on pretrained multilingual language models. arXiv preprint arXiv:2107.00676.) provide an overview of various multilingual language models (MLLMs) as well as their linguistic coverage. Some of the specific questions that they try to answer in their survey are:
- How can the benefits of BERT-like pretrained models be utilized for other languages of interest?
- For a given language, is a language-specific BERT better than a MLLM?
- Can the shared representations learned by MLLMs improve machine translation performance between two resource-rich languages?
These questions are mapped on to further specific investigations about existing work in the MLLM space, summarized in the following areas of study:
- How are various MLLMs built?
- How are MLLMs evaluated (benchmarks)?
- Are MLLMs better than monolingual models for a given language?
- Do MLLMs enable cross-lingual transfer?
- Can MLLMs be used in bilingual tasks?
- Do MLLMs learn universal/generalizable patterns across languages?
- Extending MLLMs to newer languages
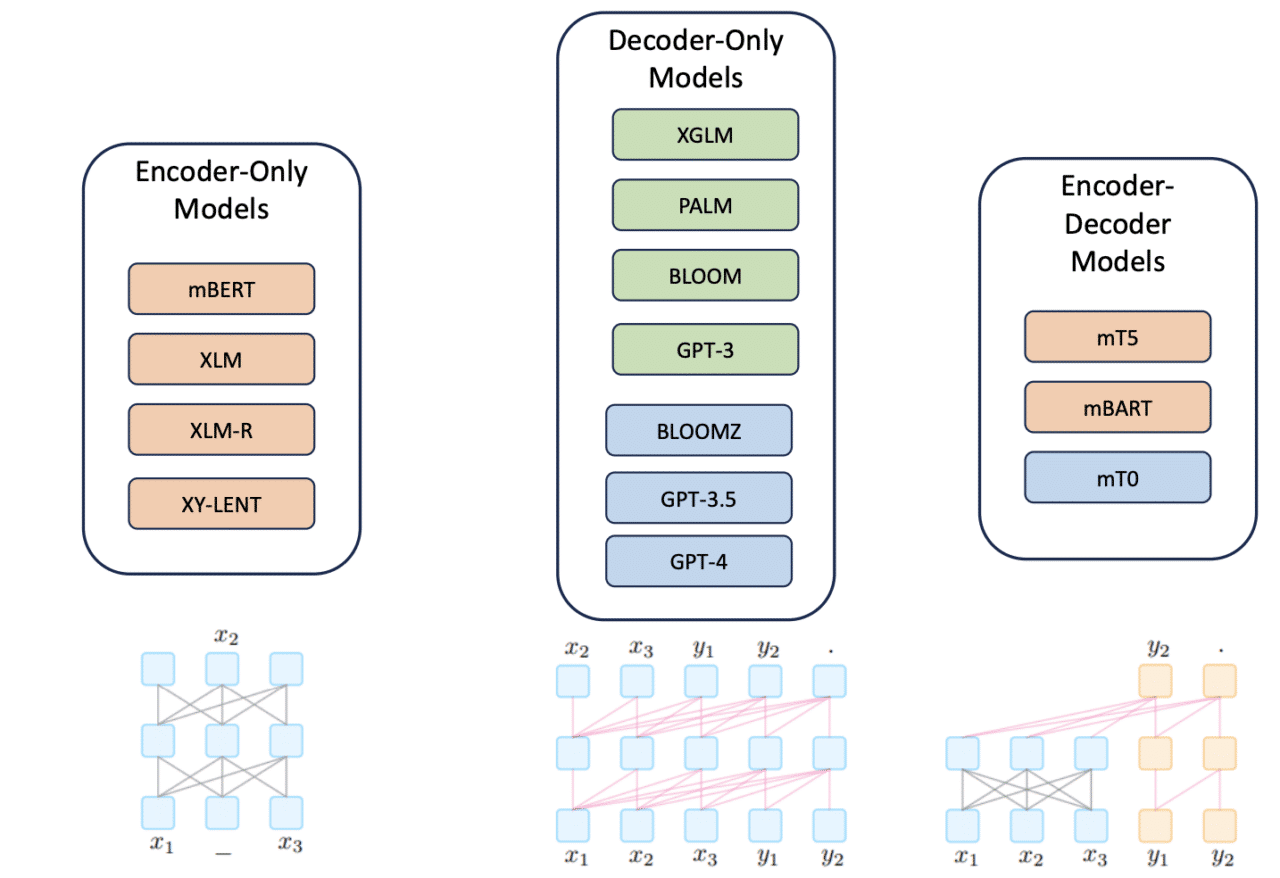
MLLM Architectures
Multilingual Language Models can be classified in terms of their respective architectures, with the three main distinctions being encoder-only, decoder-only, and encoder-decoder models. In the below figure, sourced from Sitaram et al., the green boxes denote models with no fine-tuning; orange represents models with task-specific fine-tuning, and blue represents multi-task or instruction fine-tuned models.
Training Objectives for MLLMs
MLLMs are typically pre-trained across data from multiple languages, with the intuition being that there will be cross-lingual transfer from higher resource languages to the ones without as much representation. The training objectives for MLLMs can come from monolingual objectives, such as the cross entropy loss when predicting masked tokens:
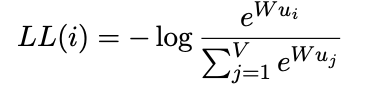
The objectives can also apply to parallel data across languages. Examples of these are the translation language model (an extension of the above metric across languages), or the InfoNCE measure (Oord, A. V. D., Li, Y., & Vinyals, O. (2018). Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748.) which is minimized for cross-lingual contrastive learning (XLCO):
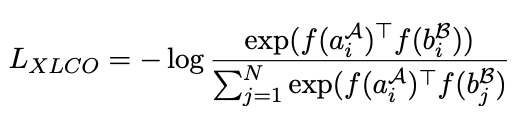
For a full list of the different metrics, please refer to Section 2 of Doddapaneni et al.
Effective Prompting for MLLMs
Once MLLMs are trained and available for use, the next task at hand pertains to prompting them effectively. Due to their multilingual nature, there are various choices when it comes to prompting strategies.
Monolingual prompting involves giving instructions in English, while the few-shot examples (if any), the test example, and the output are all in the other (usually resource-poor, or “native”) language.
Translate-test prompting, on the other hand, reverses this by restricting all the choices (instruction, few-shot examples, test example, output) to English: the output is usually back-translated.
Cross-lingual prompting sees the test example and the output in the native language.
Chain-of-thought prompting, cross-thought prompting (where the model adds an extra step of rewriting the requested content in English), and aggregation (an ensemble approach) are some other prompting strategies for MLLMs.
MLLMs and Token Lengths
Even among the so-called “high resource” languages, not all languages are created equal. Specifically in the era of large language models, the issue of tokenization of text is an all important consideration. In their work on comparing and evaluating tokenization of MLLMs on specific languages, Rust et al. find that adapting tokenizers to individual languages can greatly improve the performance of MLLMs.
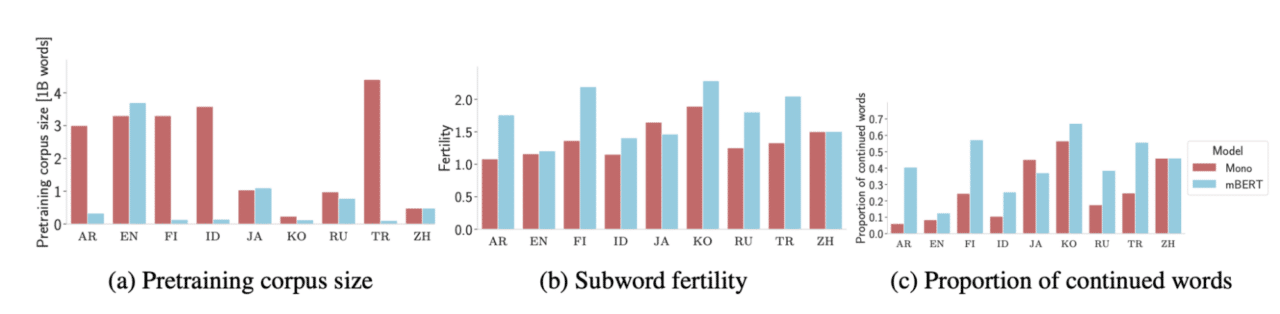
One of the paper’s key experiments concerns the actions of a given tokenizer over a language. For this experiment, they consider Arabic (AR), English (EN), Finnish (FI), Indonesian (ID), Japanese (JA), Korean (KO), Russian (RU), Turkish (TR), and Chinese (ZH); and their respective pretrained monolingual BERT models. They measure two metrics:
- Fertility: The sub-word fertility measures the “average number of sub-words produced per tokenized word”: that is, it is a measure of how aggressively a tokenizer splits.
- Proportion of Continued Words: This is the “proportion of words where the tokenized word is continued across at least two sub-tokens”, and measures how often a tokenizer splits words.
Low scores for both metrics indicate that a tokenizer is well suited to the language that it is tokenizing.
Token Budgets for LLMs
The key issue exposed by this work on MLLMs is one that applies even more urgently in the age of ubiquitous generative models: that of the “token budget”. Simply put, all uses of LLMs are subject to constraints on the number of tokens (input + output) that can be ingested and/or generated. The most common model for LLM monetization is based on token consumption, and it is the determining factor behind whether a task can be successfully tackled as an LLM task.
This issue becomes even more important when it comes to multi-party human conversations, which tend to naturally be much longer than other texts. The transcript of a typical 30 minute conversation between two parties can easily run into the range of 4000-6000 tokens, and this is merely the input: the output further eats into the user’s token budget.
However, there is an even more subtle nuance at play here. Depending on the language of input and desired output, the number of tokens required can show a very high degree of variance. Higher resource and overrepresented languages like English typically tend to split the text into fewer tokens – while underrepresented languages (like Hindi) tend to require many more tokens for semantically equivalent text.
This is very strikingly demonstrated by Yennie Jun’s tokenizer dashboard, which visualizes the token distribution for multiple languages on data from the validation set of the Amazon Massive dataset. Here is a visualization of the token distribution for English, Spanish, French, German, Chinese, and Hindi; over two tokenizers – (1) OpenAI’s GPT-4 tokenizer; and (2) the sentence-transformers model.
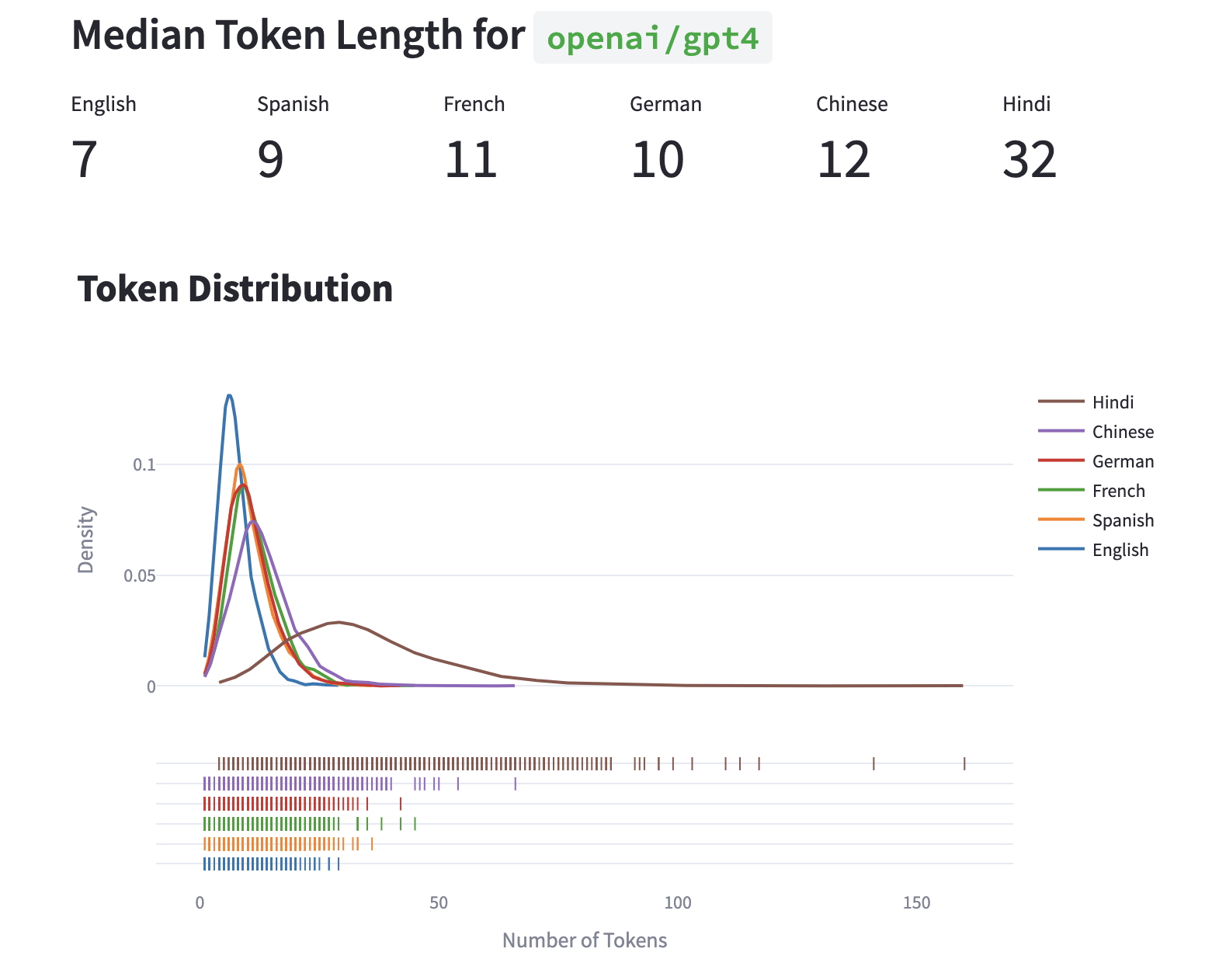
Notice that all the languages except Hindi tend to cluster around a much lower median token length, with English being the lowest: the median token length for a Hindi instance is nearly 5 times as large.
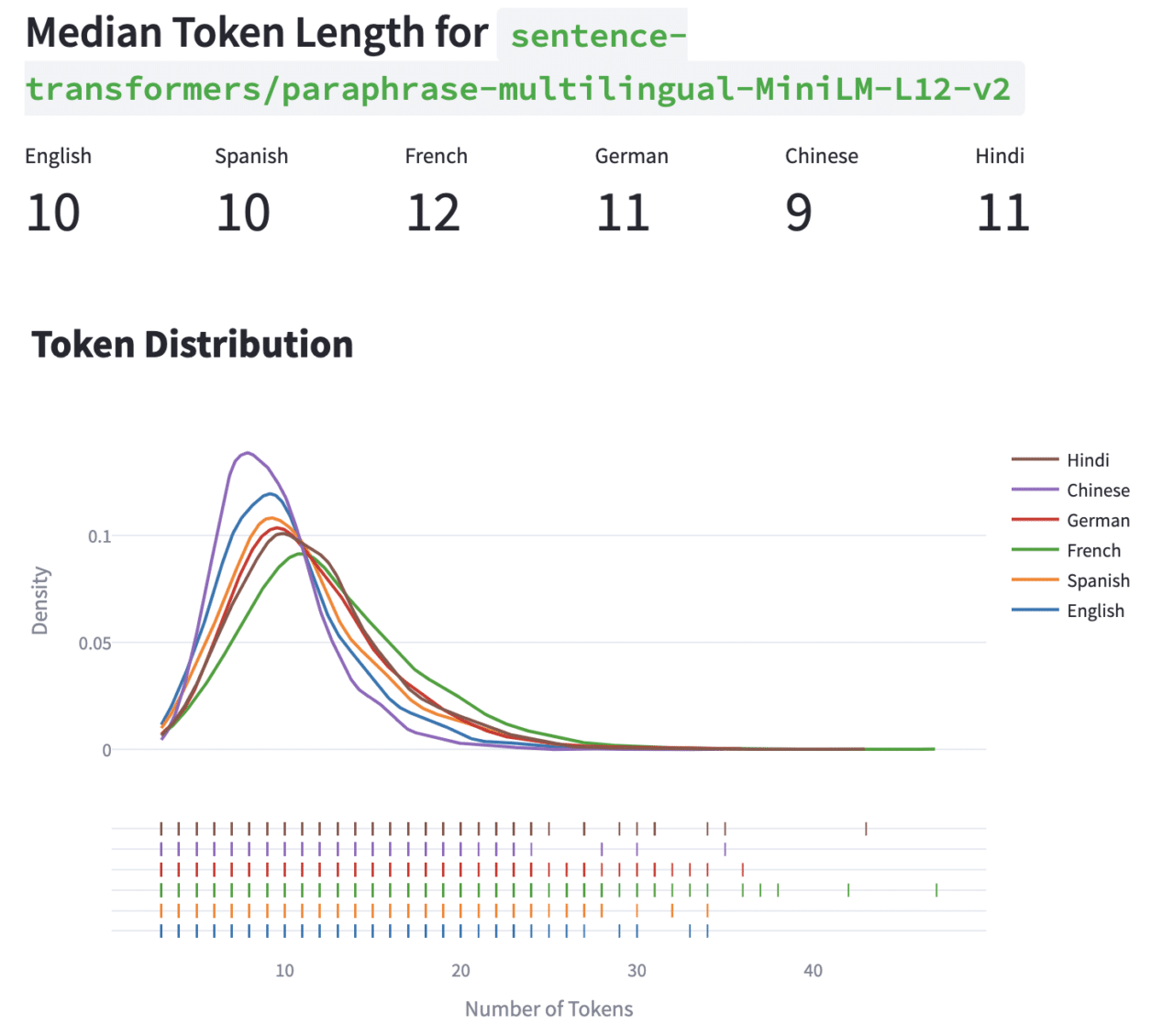
This effect changes by the model used – the same plot using the sentence-transformers tokenizer shows a much closer clustering of the medians for all the languages. Chinese is actually the lowest here, at 9 tokens.
This demonstrates pretty starkly that for a fixed token budget, overrepresented languages like English will get the user more bang for their buck – even if this is a totally unintended downstream side effect of the lack of linguistic diversity in the world of NLP.
Nebula: A Multilingual LLM for Human Conversations
At Symbl.ai, we have been working on our Nebula family of models for multi-party human conversations. We address the problems discussed in this post in two fundamental ways:
- Context Window Length: Understanding the importance of a larger context window to accommodate the natural length of multi-party human conversations, our models come with out of the box support for longer contexts. Nebula’s base and enhanced models both support context window lengths of 8K at present, with support for 16K coming very soon. This larger context length also helps correct some of the imbalance showcased in the earlier section, where languages other than English often tend to consume a larger token budget for equivalent text.
- Multi-language Support: Nebula also comes with out of the box support for languages other than English. This works on both inputs and outputs: you can give it input in one language (e.g. French) and instruct it to produce output in another (e.g. Spanish). We are currently working hard to address the problem of data distribution disparity when it comes to multilingual support and to provide support for more languages of interest for business use cases in various geographies around the world.
The animations below show two examples that reflect two different prompting strategies for multilingual tasks in Nebula. In the first example, the input context is in English, and shows a customer support call where a customer is having difficulty with their internet connection. The support agent leads the customer through some common questions and resolutions, and ends up scheduling a technician visit. Nebula is able to understand instructions (in English) that ask for a summary to be produced in different languages (French, Spanish, Italian); as well as instructions in German to produce a summary in the same language.
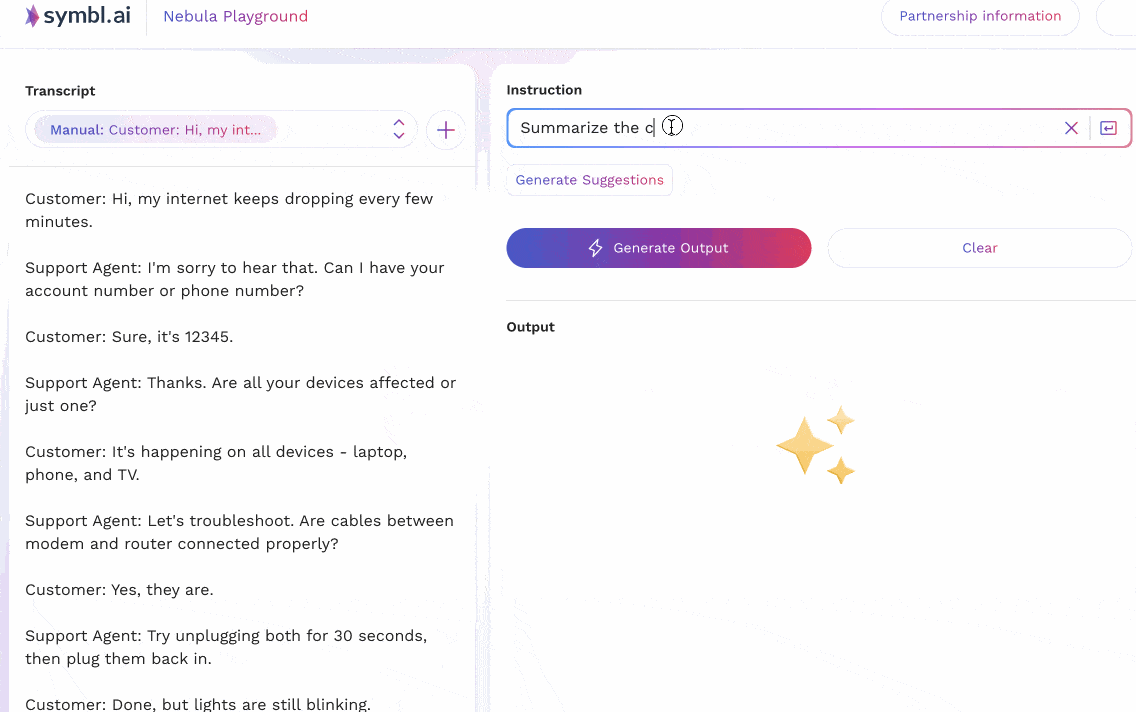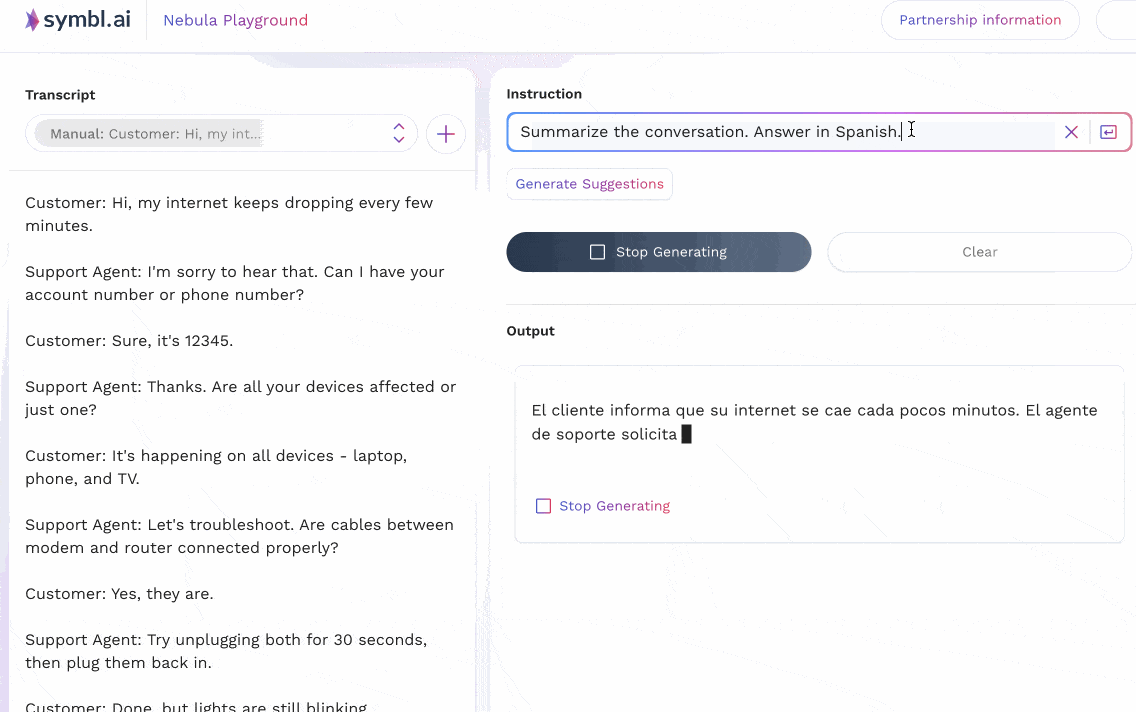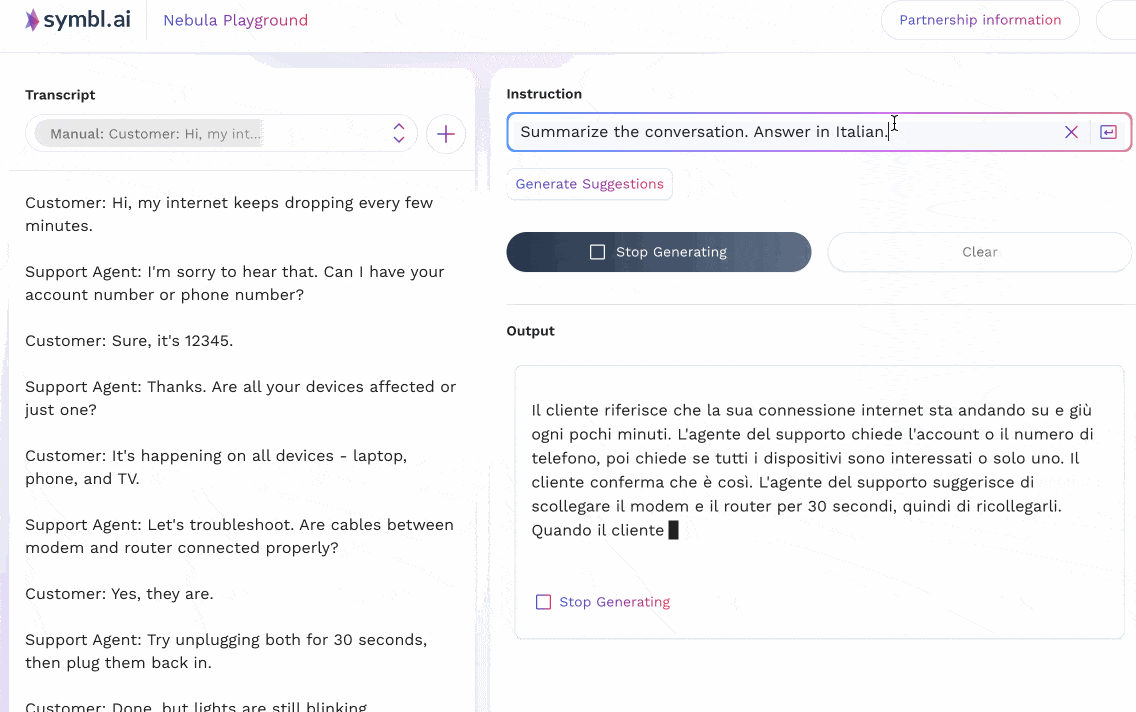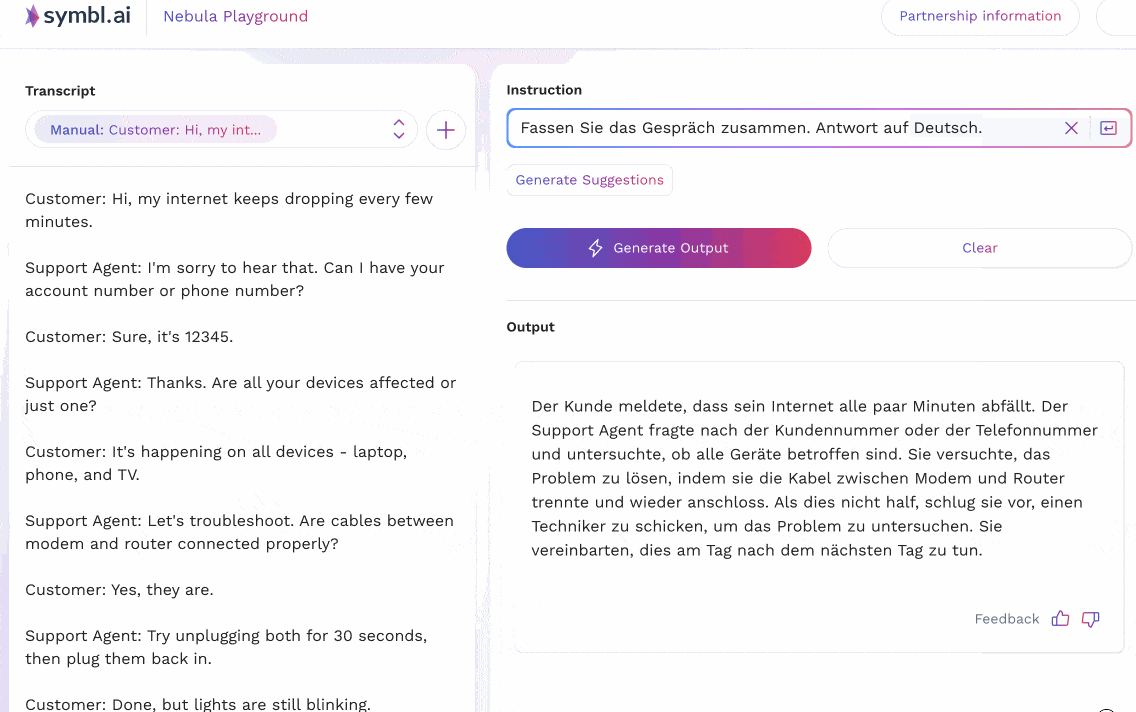
In the second case, an equivalent version of the conversation above – translated to French – is given to the model as input. Instructions are then passed to it to summarize the conversation in other languages (Spanish, German, Polish).
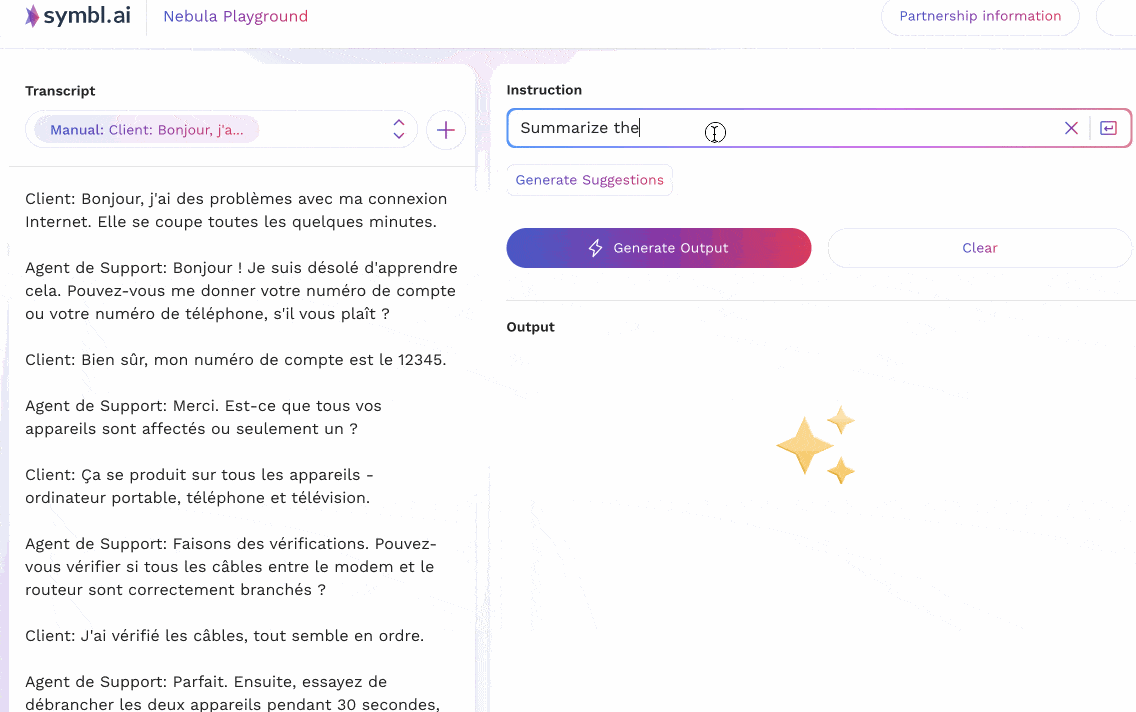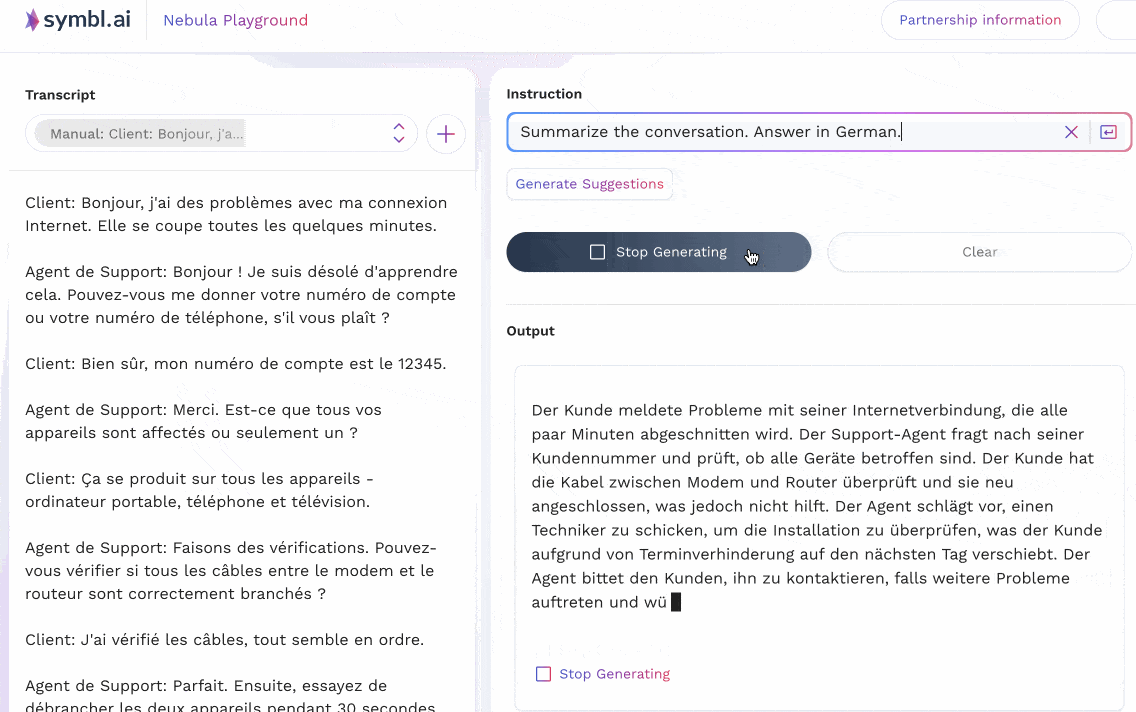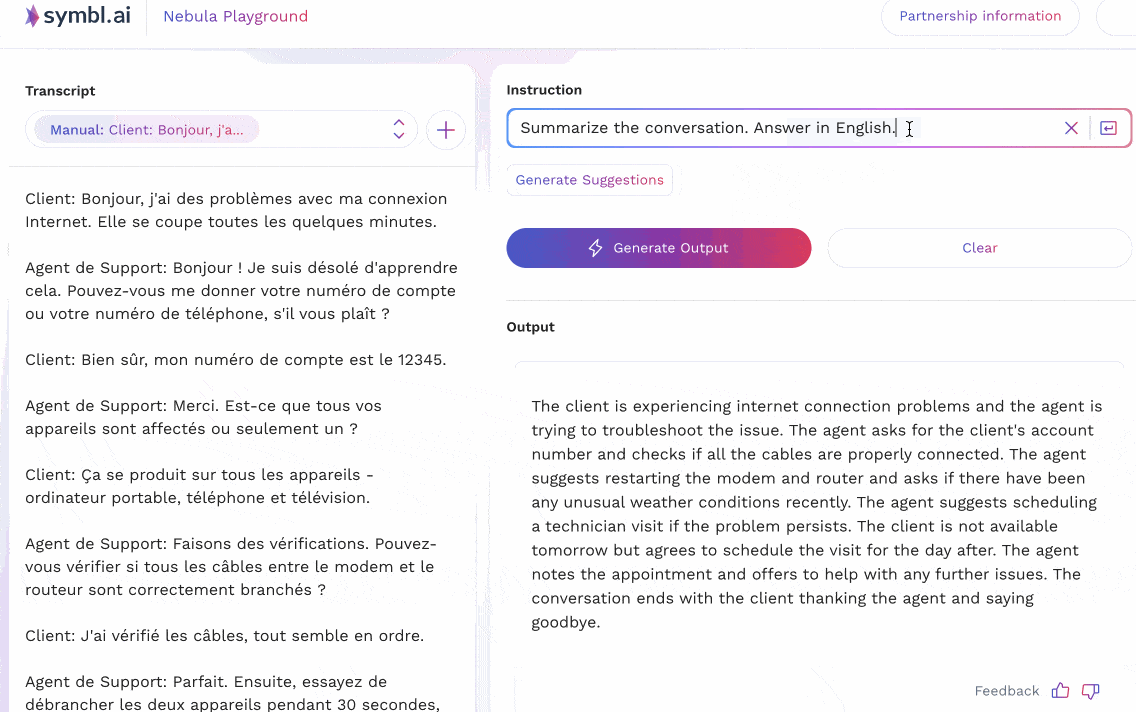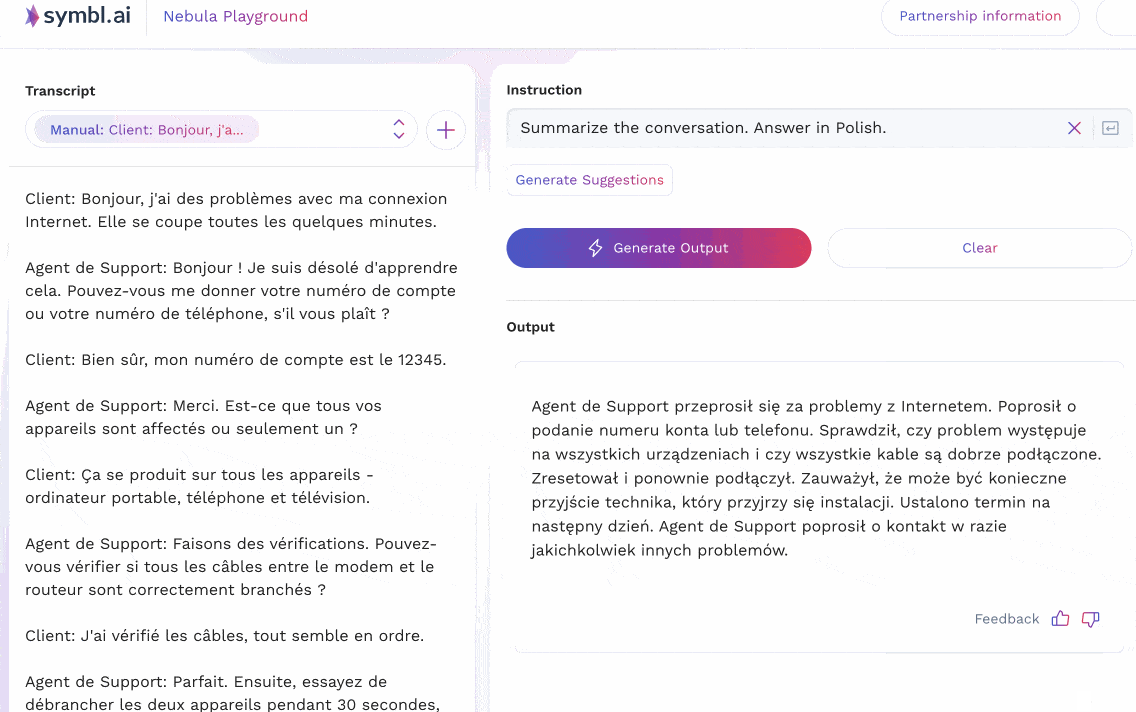
Nebula is thus able to successfully deal with inputs, outputs, and instructions in various non-English languages. We truly believe that multilingual support lies at the heart of supporting LLM-based conversational intelligence for enterprise and business use cases around the world; and are devoting our efforts to increase representation across world languages.