
Overview
Retrieval-Augmented Generation (RAG)1 is revolutionizing the way we think about machine learning models for natural language processing. By combining retrieval-based and generative models, RAG offers highly contextual domain specific responses. This guide will walk you through the steps to implement RAG using Nebula LLM, Nebula Embedding API, and vector databases.
Why RAG? Comparison to Traditional Models
Generative Models: Generative models, like GPT or BERT, are trained on a large corpus of data but do not have the ability to pull in real-time external information. They rely solely on the data they were trained on, which can sometimes be a limitation for tasks that require up-to-date or specialized information.
Retrieval Models: These models are good at pulling specific pieces of information from a large corpus but may not be adept at synthesizing or generating new text based on that information.
RAG: Combines the best of both worlds. It can retrieve real-time or specialized information from an external corpus and then use a generative model to create coherent and contextually relevant text.
Use-cases of RAG
Question Answering
- Open-Domain QA: When you have a corpus of data that spans multiple subjects or domains, RAG can be used to answer questions that may require piecing together information from multiple documents
- FAQ Systems: For businesses that have frequently asked questions, RAG can automatically pull the most up-to-date answers from a corpus of documents
- Research Assistance: In academic or professional research, RAG can help find and compile information from various sources
Document Summarization
- Executive Summaries: RAG can compile executive summaries of long reports by pulling key insights from latest data
- News Aggregation: It can pull from multiple news sources to generate a comprehensive summary of a current event
- Legal Document Summaries: In law, summarizing lengthy contracts or case histories can be efficiently performed
Chatbots
- Customer Service: A RAG-based chatbot can pull from a knowledge base to answer customer queries, reducing the load on human agents
- Technical Support: For software or hardware troubleshooting, RAG can pull from a database of common issues and solutions
- Personal Assistants: RAG can make virtual personal assistants more versatile by enabling them to pull from an extensive database of information
Data Analysis
- Market Research: RAG can analyze a large corpus of customer reviews, social media mentions, etc., to provide insights
- Financial Analysis: It can pull historical data and analyst reports to generate insights into stock trends or company performance
- Healthcare Analytics: In healthcare, RAG can analyze medical records, research papers, and clinical trial data for analytics
Content Generation
- Article Writing: Journalists or content creators can use RAG to automatically draft articles that incorporate the latest data or references
- Report Generation: In corporate settings, RAG can generate quarterly or annual reports by pulling data from various internal databases
- Educational Content: For educational platforms, RAG can generate quizzes, summaries, or study guides based on a corpus of educational material
RAG’s Application in Specific Industries
- Customer Support: In a customer support setting, RAG can assist agents by pulling from a knowledge base to provide more informed and precise answers to customer queries
- Healthcare: In healthcare, RAG can assist in pulling patient histories, medical journals, or drug interactions to assist medical professionals
- Finance: RAG can be used to pull real-time financial data or historical trends to assist in decision-making processes
- Legal: RAG can assist in document discovery processes by retrieving relevant case law or statutes
- Retail and E-commerce: RAG can be used to generate personalized product descriptions or recommendations based on user behavior and other external data points
Data Safety in Enterprises with RAG
- Data Isolation: In an enterprise setting, the corpus of data from which the retriever pulls information can be isolated and secured within the company’s own infrastructure
- Access Control: Fine-grained access controls can be applied to the data sources to ensure that only authorized models or users can access the sensitive information
- Data Encryption: Data can be encrypted at rest and in transit to ensure confidentiality and integrity
- Audit Trails: All data retrieval and generation events can be logged to provide an audit trail for compliance purposes
- Data Masking: Sensitive information can be masked or redacted in the retrieved documents before they are used for generating responses
Implementation
Prerequisites
- Check access to Nebula. If you do not have access, you can sign-up here
- Generate an access token
Building a Vector Database of Transcripts
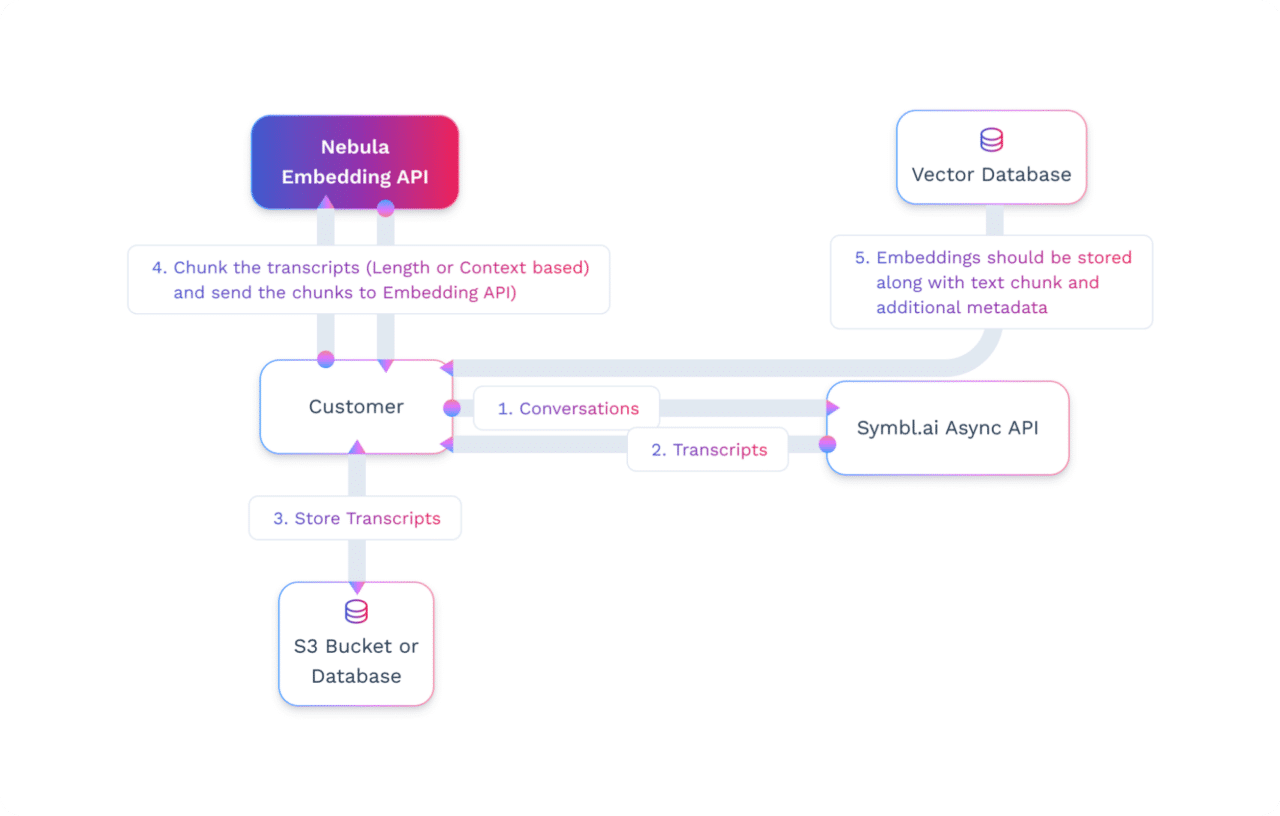
- Build the Database of Transcripts: Transcribe calls using Symbl.ai Async API and store transcriptions in a database, e.g., S3.
- Chunk Conversations: Break each transcript into meaningful parts. This could be length-based or context-based. Here is a resource on the chunking strategies.
- Create Embeddings: Use Nebula embedding API to create embeddings for each chunk. Use the below code to create embeddings.
curl --location 'https://api-nebula.symbl.ai/v1/model/embed' \
--header 'ApiKey: <api_key>' \
--header 'Content-Type: application/json' \
--data '{
"text": "Dan: Definitely, John. The first feature we'\''re introducing ...."
}'- Store the Embeddings: Once the embeddings are created, store them in a vector database for retrieval based on queries to the LLMs along with transcript chunks and any required metadata useful for adding additional criterias while querying (e.g. customer id, date/time, etc.).
Note: Check Appendix for more details on Vector database2
For more information about using embeddings, see the Embedding API guide.
Generate Response from Nebula LLM
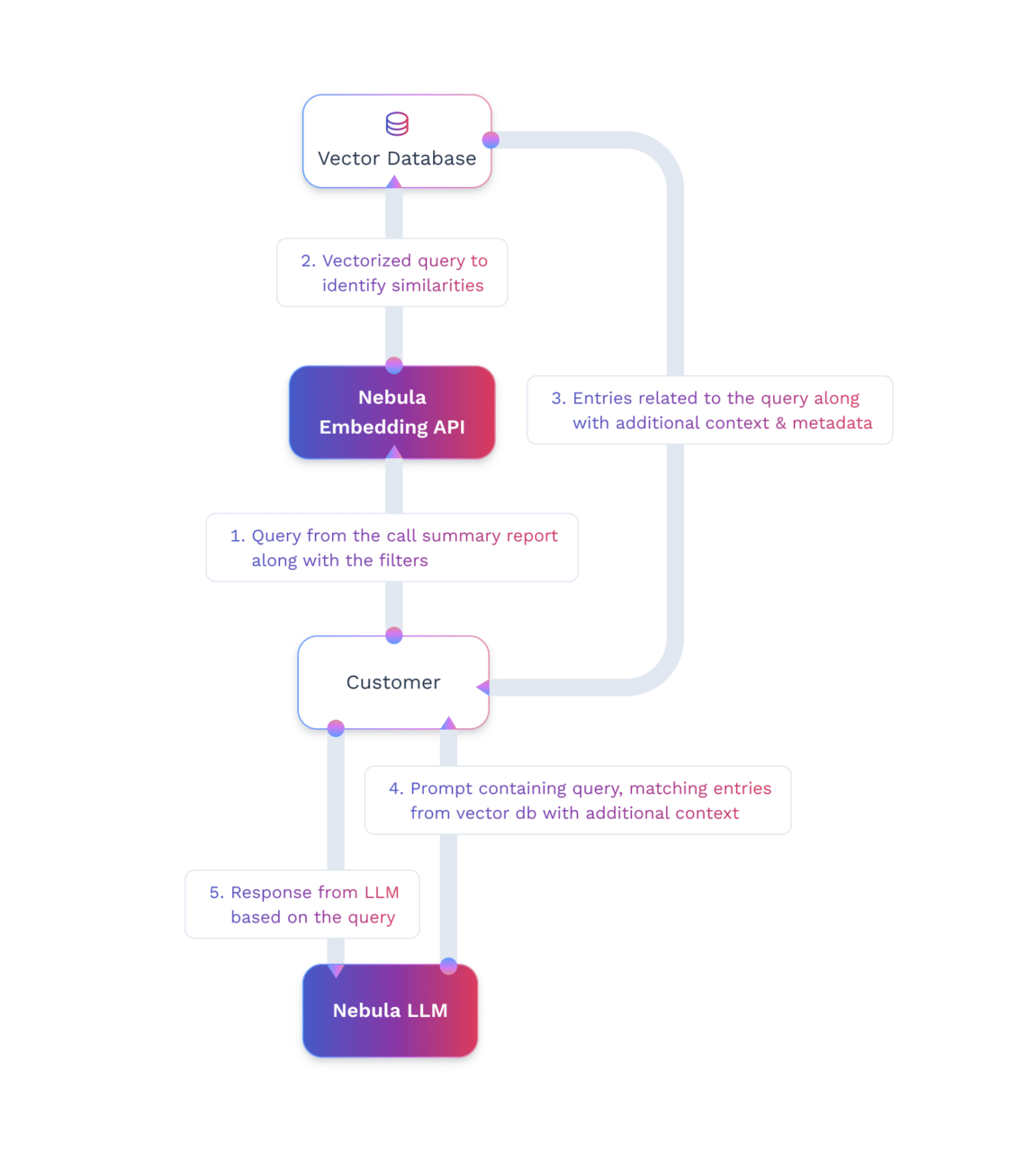
- Query Processing: Users can query directly from User’s UI to Nebula Embedding API. The query is processed by Nebula’s Embedding Model to create a query vector.
- Vector Matching: This query vector is matched against stored vectors in the vector database to find similar data from conversations based on the query.
- Context Construction: The matched vectors and the corresponding text chunks of transcripts stored in the vector database are used to build the prompt context for Nebula LLM. The prompt with this context is further passed to Nebula LLM by the User server.
- Response Generation: The pre-processed query string along with the newly created context from the vector database is sent to Nebula LLM to analyze the context and the query to generate a relevant response. This response is displayed on the User’s UI.
Appendix:
- Learn more about RAG: https://research.ibm.com/blog/retrieval-augmented-generation-RAG
- What kind of vector database?: Options include specialized vector databases like Weaviate, Milvus, Pinecone, Vespa.ai, Chroma, Nomic Atlas, and Faiss.Additional database like ElasticSearch, Redis which have additional metadata support, scale, speed and more, can also be considered which also provide support for vector embedding.
- Additional Pricing: Open-source databases like Faiss and Milvus are generally free but require manual setup and maintenance. Managed services like Pinecone and cloud-based solutions like Weaviate, Vespa.ai will have a cost based on usage