
Retrieval-Augmented Generation (RAG) is a technique that combines retrieval-based and generative AI models to produce highly contextual domain-specific responses. There are numerous applications for RAG: Question & Answering, Summarization, Report Generation, and more. In his recent blog, Yujian Tang (Zilliz) elaborates on the tech stack that is needed to implement a simple conversational RAG application using Symbl.ai’s domain specific foundation model, Nebula. Below is a summary of the implementation:
Technology stack
- Nebula LLM:
Symbl’s Nebula LLM is a domain specific pre-trained foundation model for interaction data. It serves as the generative model replacing OpenAI’s GPT-3.5 in this project by Zilliz - Milvus Vector DB:
Milvus serves as the vector database for storing vectors derived from conversation data on which similar matching is performed and relevant information is extracted for feeding the Nebula LLM - MPNet V2 Embedding Model from Hugging Face:
MPNet V2, an embedding model from Hugging Face, is used in place of OpenAI embeddings to derive embeddings from conversation data and user search queries - LangChain:
LangChain serves as an orchestration framework. Key components used for creating conversational memory for the application are: the vector store retriever memory, conversation chain, and prompt template object
High Level Implementation
- Install required libraries such as LangChain, Milvus (Lite), PyMilvus, python-dotenv, and Sentence Transformers
- Load API key for Nebula (Register to request a key)
- Initiate vector database and embedding model
- Create a sample conversation and save it to memory as context using VectorStoreRetrieverMemory
- Import Nebula LLM by using the API key
- Create a prompt template including user query using PromptTemplate
- Create a conversation chaining the Nebula LLM, memory, and prompt using ConversationChain for asking a question
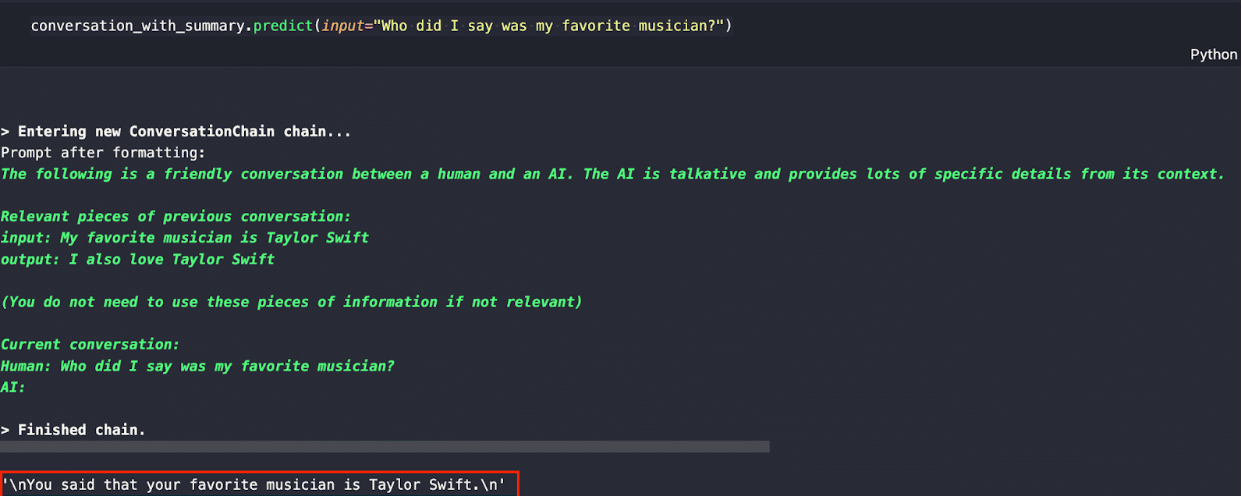
Output Image (Reference: https://zilliz.com/blog/building-rag-apps-without-openai-part-I)
Conclusion
As businesses and users start focusing on the specificity of output and outcome from LLMs, the use of domain specific models like Nebula is gaining prominence. The Nebula Embedding Model is also trained on interaction data, and can produce high quality vector embeddings on conversational data and knowledge.
You can read about the full implementation of this RAG-based conversational system, along with code samples, at the blog published by Zilliz.