
The conversation intelligence system for your product can range from a simple rule-based engine with speech recognition that is applied to a specific domain or use case, to a complex, continued contextual understanding system that can work across different (open) domains and sources of data.
After reading what conversation intelligence is, and the skyrocketing need of such a platform for every business or product, here we will share how you can build a conversation intelligence system effectively.
Conversation intelligence technology landscape
Here’s an overview of the entire conversation AI/intelligence landscape:
- Text analysis for reviews, change-request emails, and social conversations
Analysis for things like text classification, entities, topics, and sentiment and your own custom keywords or intents. Conversation intelligence for text is great for mining short form conversations where sentence structure is more precise and organized because it can identify and structure facts, relationships, and assertions that would otherwise remain buried in the mass of natural conversation.
- Human to machine conversations
These are chatbot or voicebot frameworks with custom intents and named entity recognition for domain or use-case specific intents (e.g. Rasa, DialogFlow). It’s great for building bots that solve specific problems by conversing with humans to do things like book a flight, check the weather, open a support ticket, find restaurants, etc.
- Human to human conversations
These are ideal for making sense of human to human conversations, like sales conversations, brainstorming meetings, Slack chats, emails, etc. For example, during customer care calls, conversation intelligence can detect whether it’s a new or returning customer, if their voice is showing negative emotions, and suggest the agent’s next actions.
The conversation intelligence workflow
The conversation intelligence workflow has three stages:
- Automatic Speech Recognition (ASR)
- Natural Language Processing (NLP) or Natural Language Understanding (NLU)
- A user experience layer (UX/UI) for voice intelligence capable of turning the NLP results into actionable insights and presenting them to the user in real-time or after the conversation has ended.
Open domain or closed domain system
When thinking about how to scale your system for other types of conversations, you’ll first need to consider what approach to build it with. Open domain and closed domain are two very different approaches to building a conversation understanding system (CUS). You can use either for H2H conversations, depending on the scope and complexity of the conversation and the data sources that exist in your product.
- Open domain systems are ideal for free-flowing conversations that involve broad and versatile conversations (such as engineering discussions, product meetings, consulting sessions) that occur horizontally and the outcomes of which vary depending on the type of conversation.
- Closed domain systems are better for known, scoped, conversations with limited outcomes where there is less unknown and a pattern can be easily recognized from a fixed data set.
A closed domain conversation intelligence system is built to understand only specific kinds of conversations, for instance, sales calls or customer support interactions. This is typically achieved using traditional supervised learning techniques which makes such systems practically useless when applied to other domains or types of conversations. And because training data gathering, data clean up, model research and development, benchmarking, deployment, and continuous maintenance of models become an overhead, it makes it almost impractical to scale for any product that can understand H2H conversations without being biased towards a specific domain or type of conversation. But an open domain system by its nature avoids all these challenges. It’s not built to understand only specific kinds of conversations, but rather to understand language and conversations at a fundamental level. Both have pros and cons – so, you should make a conscious decision early on when building this for your product, understanding the future roadmap for your business. Symbl.ai is an open-domain system that allows it to scale across any conversation intelligence use case. This means that whether you are building an application specifically for the sales domain, a general-purpose meeting, or collaboration application, you can leverage the benefits of Symbl’s AI capabilities equally without having to build and train machine learning models.
Getting started
Based on whether you decide to build a closed domain or an open domain system, there are three stages to building conversation intelligence system:
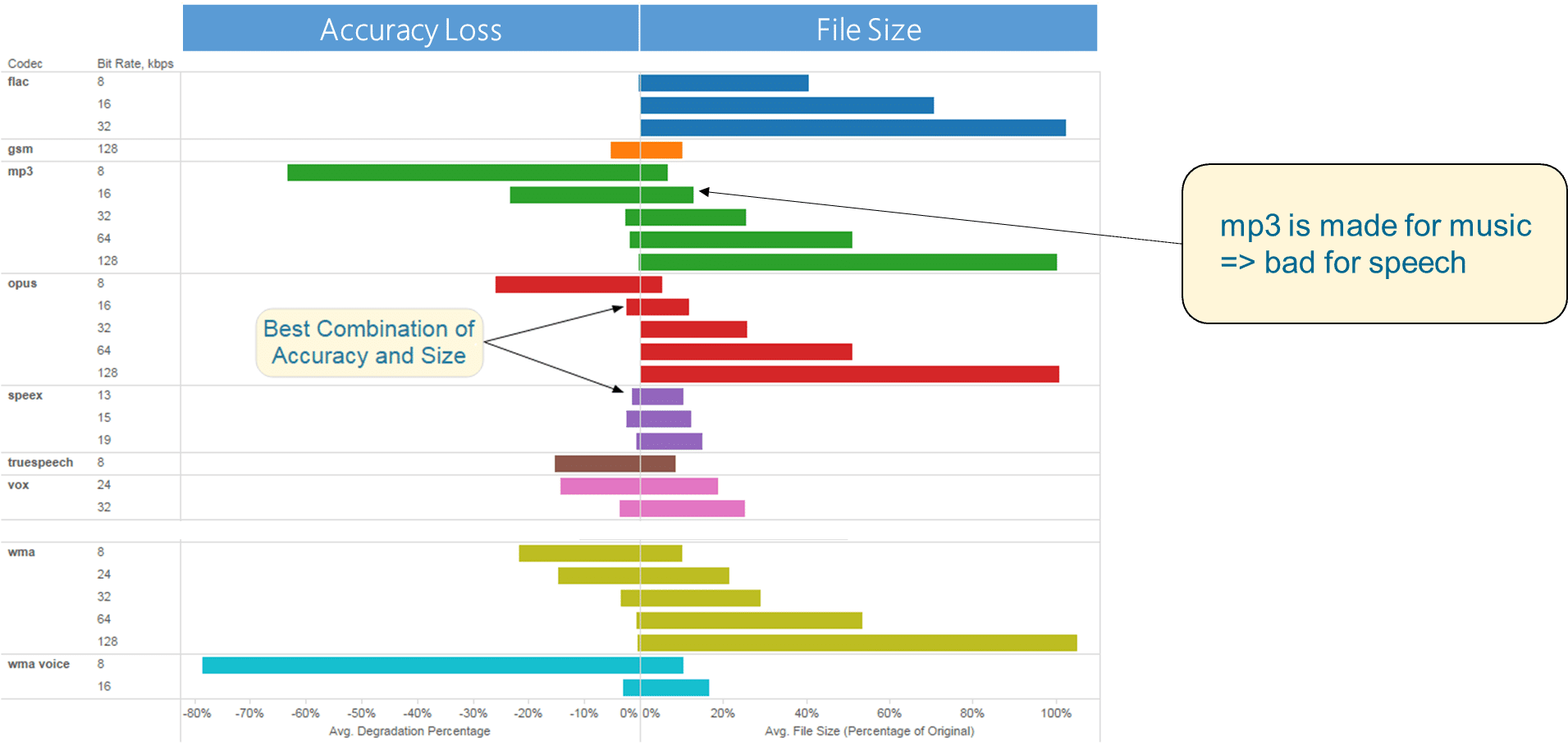
1. Start with speech recognition – To begin, you must determine a number of key factors. First, you need to know whether your application will be used for real-time or asynchronous conversations. You can determine this from the types of communication you will be using; for example, a phone chat or team meeting will require real-time speech recognition; whereas a video recording or information from an email or document are asynchronous forms of communication. You also need to identify all the languages and dialects your application might encounter. You can find this out by considering historical data that you have available, and by asking your client/the business who and how the application will be recording, considering factors like the geographical conversation sources. Consider the channels it will be used for too, and their associated audio quality. You should determine whether/how much the recording files have been compressed to prioritize storage efficiency over audio quality. The most effective change you could make would be to ensure your recordings are capturing high quality audio; the ideal format would be lossless audio formats like LINEAR16 (PCM) or Free Lossless Audio Codec (FLAC) with a minimum of 16 kHz sample rate, which is optimal for human speech. In addition, you should assess the level of background noise and the subsequent Speech to Noise Ratio.
2. Build the required machine learning framework – This can be approached in several ways depending on the scope and required outcome of the conversation intelligence system you are building. The first step is to decide upon your strategy. Conversation intelligence generally uses intent based systems which is a classification model built with supervised learning. Supervised learning algorithms are trained using labeled data. You’ll need to gather the training data in huge amounts to get started which can be an expensive activity. The simplest way to build any model is to write rules. However, rules don’t scale, and they never generalize. As your system becomes more complex, designing and developing rules becomes an exponentially harder challenge, as does translating those rules into code. Then, you’ll need to tell your AI system specifically what to look for, and this is how the model is trained until it can detect the underlying patterns and relationships. These steps will enable it to provide good results when presented with new data. To make your system as sophisticated as possible, you need to incorporate deep understanding techniques. Deep learning alone is where the system is trained, or just programmed, but add deep understanding into that and the system is educated. Supervised learning is good at classification and regression problems, this might be determining sales volumes for a future date. The aim in supervised learning is to make sense of data toward specific measurements. A more advanced approach would be to build an open-domain system. Such a system has an inherent ability to learn on its own and automatically generalize the meaning of the concepts and the cause-effect relationships of them. This enables the system to take away most of the problems. 3. Continuously train and maintain the machine learning model – Once you’ve built your model, you need to train it to make it as accurate and robust as possible. This requires a vast set of training data to begin with and a feedback loop to help the model learn from previous iterations. You’ll continuously need to mitigate biases in the training data. Because the training data itself is created by human beings it has inherent human biases, and as more people start using it those biases need to be normalized. This is a long and intensive process in supervised learning-based models. Identifying and eliminating sources of bias are critical to model accuracy. In addition, be prepared to tackle challenges like data cleaning, and hyperparameter tuning. If you are able to successfully build an open-domain system, or choose a vendor that uses an open-domain system, your applications will scale and reach your users much faster than traditional machine learning techniques.
Build a smarter model
Any learning system always benefits by looking at more data. The way it uses the data to learn defines how good it will be at learning, generalizing that learning, and how fast it can learn. One of the exciting features of this type of AI is the ability for human conversations to be understood in absolute real-time: recording and processing the conversation as it happens. You’ll need an API interface to do this, and you need to bring a layer of structure onto that by integrating speech. Speech recognition is a completely analog structure upon which you build the intelligence. You can build the model data analysis to target certain problems. For example, if you want to build an application that listens and takes important information from a conversation, you need to:
- Build the data set
- Design your machine learning
- Write the code
You’ll also need a way to ingest your conversation data, either textual or speech-based. Inevitably, you’ll have to devise solutions that can tackle problems during both real-time and recorded conversations. In either case you’ll need a speech recognition system that can do all of this and work with a high level of accuracy. Remember, this is always going to be a long process, but the more data you can gather and fine-tune, the more sophisticated your AI will be. You can experiment with Symbl.ai‘s standard version API to build your intelligence features for conversations, without any need to gather more data or worry about deploying and maintaining complex machine learning and deep learning models. The next post in our series looks into the different applications for your conversation intelligence system. Further reading:
- The 5 components towards building production-ready machine learning systems
- Contextual Disambiguation