
Last month, I was at the 37th meeting of the Neural Information Processing Systems conference – otherwise known as NeurIPS. Over the past decade, NeurIPS has become the preeminent research venue for the presentation of advances in Machine Learning and Artificial Intelligence. This year was no different, with 3586 papers accepted for presentation in the conference’s main track – and many others in the various workshops and auxiliary events held during the conference.
In general, this edition of the conference continued the trend of increasing attendance and interest in NeurIPS. The exhibitor hall was packed to the brim with companies large and small, enterprise and startup – and each poster session was a sea of humanity. A significant portion of the interest in this particular edition of NeurIPS was focused on large language models (LLMs) and the ecosystem around them – the theoretical foundations; architectures; data and ops pipelines for pretraining, fine tuning, and alignment; their applications; and what LLMs cannot yet do (tl;dr: think planning and generalized reasoning).
Below, I dive into the details of 11 papers and/or talks that caught my attention at the conference – these run the gamut from reinforcement learning (a topic of perpetual interest at NeurIPS) to pretraining and fine tuning of LLMs, multilinguality, and explorations of various emergent properties of language models including planning and reasoning.
Optimistic Exploration in Reinforcement Learning Using Symbolic Model Estimates
“Optimistic Exploration in Reinforcement Learning Using Symbolic Model Estimates” investigates the possibility of speeding up the learning process in reinforcement learning by generalizing learned model dynamics across similar actions with minimal human input. The paper introduces a new method for learning optimistic symbolic approximations of the underlying world model and evaluates it by testing it on multiple benchmark domains to compare it with other RL strategies.
The authors suggest that their new method enables reinforcement learning agents to optimistically explore an unknown dynamical system to solve multiple downstream tasks in a zero-shot manner.
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models
This paper discusses surprising differences in causality-based localization compared to knowledge editing in language models. The authors found that localization conclusions from representation denoising do not provide insight into which model layers would be best to edit in order to override an existing stored fact with a new one. The authors raise questions about how past work relies on causal tracing to select which model layers to edit. The authors go on to consider variants of the editing problem, including erasing and amplifying facts, and find that in one case editing performance does relate to localization results from representation denoising, but that which layer is edited is a better predictor of performance.

On the Planning Abilities of Large Language Models – A Critical Investigation
“On the Planning Abilities of Large Language Models – A Critical Investigation” investigates and evaluates the planning capabilities of Large Language Models (LLMs).
The study aims to evaluate two aspects:
- The effectiveness of LLMs in generating plans autonomously in commonsense planning tasks
- The potential of LLMs as a source of heuristic guidance for other AI planners in their planning tasks
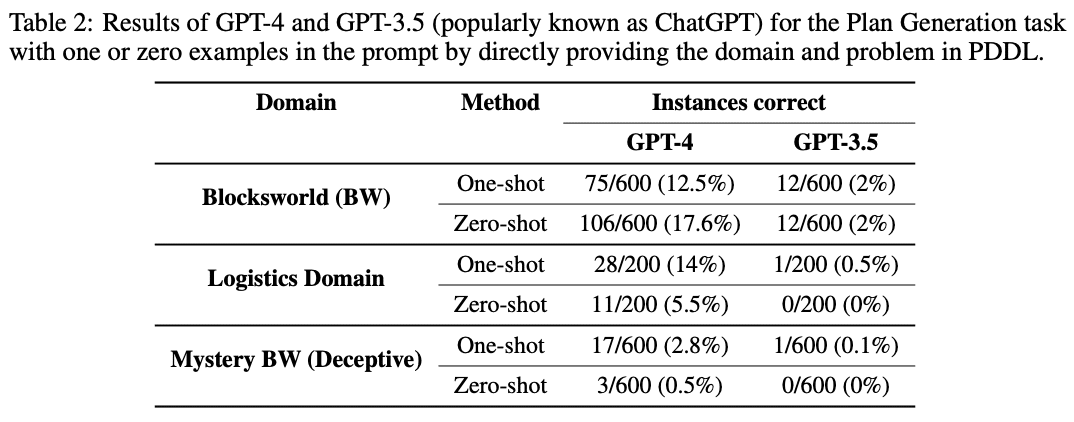
The authors conduct a systematic study by generating a suite of instances on domains similar to those employed in the International Planning Competition and evaluate LLMs in two distinct modes: autonomous and heuristic.
Their findings reveal that LLMs’ ability to generate executable plans autonomously is rather limited, with the best model (GPT-4) having an average success rate of ~12% across the domains. However, the results in the heuristic mode show more promise. In the heuristic mode, the authors demonstrate that LLM-generated plans can improve the search process for underlying sound planners and that external verifiers can help provide feedback on the generated plans and back-prompt the LLM for better plan generation.
Overall, the paper raises questions about the emergent planning capacities of LLMs and suggests that more research is needed to fully understand and tap into their potential for planning complex tasks.
QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA is an efficient finetuning approach for quantized LLMs that reduces memory usage without sacrificing performance. QLoRA achieves this by backpropagating gradients through the frozen 4-bit quantization of a pretrained language model into low-rank adapters (LoRA).
The developers of QLoRA used the method to finetune more than 1000 models, providing a detailed analysis of instruction-following performance across 9 instruction datasets and model types (LLaMA, T5). Their results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous standard.
Toolformer: Language Models Can Teach Themselves to Use Tools

“Toolformer: Language Models Can Teach Themselves to Use Tools” presents a novel approach to training language models to use external tools via simple APIs in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. This is done by training the model to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction.
The paper shows that Toolformer models can achieve substantially improved zero-shot performance across a variety of downstream tasks and can often compete with much larger models without sacrificing its core language modeling abilities.
Panel: Beyond Scaling – Alexander (Sasha) Rush, Aakanksha Chowdhery, Angela Fan, Percy Liang

The Wednesday afternoon plenary session of the conference featured a panel on “LLMs: Beyond Scaling”, with researchers from Stanford/Together.ai, Meta, and Google moderated by Alexander Rush from Cornell/Cornell Tech. The panel delved into the complexities of training and deploying LLMs at massive scale, and some of the key issues beyond merely scaling such LLMs for end-users.
The most notable discussion coming out of this panel was the participants’ reluctance to go into the details of the various models that they were describing: most of the discussion was anecdotal and abstract. This engendered questions at the conference around the debate on closed and proprietary models versus open source models; and the propriety of discussing only proprietary models in a venue such as NeurIPS, meant for open dissemination of research results and techniques. This is likely a debate that has only just begun, and will continue well into 2024.
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
“Tree of Thoughts” (ToT) is a new framework for language model inference that extends the popular Chain of Thought approach to prompting language models. ToT enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT lets language models look at larger pieces of text, consider different options by following different paths of reasoning, evaluate their own decisions to determine the next course of action, and look ahead or backtrack when necessary to make global choices or fix errors.
The ToT method has been shown to significantly improve problem-solving abilities in language models on tasks that require non-trivial planning or search, such as Game of 24, Creative Writing, and Mini Crosswords.
Why think step by step? Reasoning emerges from the locality of experience
“Why think step by step? Reasoning emerges from the locality of experience” investigates the inherent reasoning capabilities of humans and large language models. By working through a series of mental steps, humans can make inferences that would be otherwise impossible. This paper tests the effectiveness of reasoning in language models and concludes that reasoning is only helpful when the data is locally structured with respect to dependencies between variables.
Are Emergent Abilities of Large Language Models a Mirage?
“Are Emergent Abilities of Large Language Models a Mirage?” explores the idea that large language models display emergent abilities not present in smaller models. The paper provides evidence that these emergent abilities may not be a fundamental property of scaling AI models and suggests that they may instead be tied to the specific metrics chosen to evaluate a given model’s performance.
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
“Direct Preference Optimization: Your Language Model is Secretly a Reward Model” suggests that large language models can be fine tuned to align with human preferences using a method called Direct Preference Optimization (DPO), which the authors claim is stable, performant, and computationally lightweight.
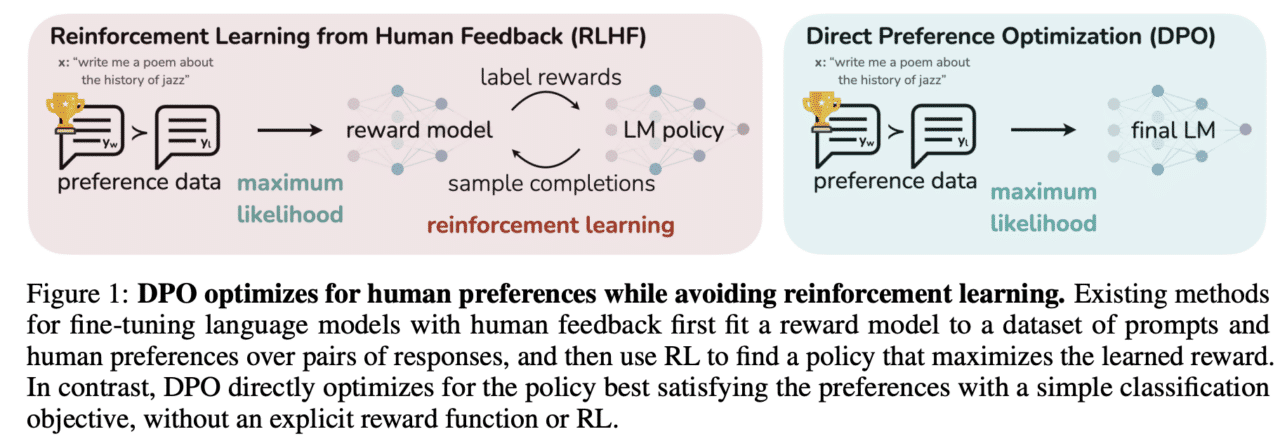
The authors argue that DPO eliminates the need for complex processes such as fitting a reward model, sampling from the language model during fine-tuning, or significant hyperparameter tuning. Instead, DPO leverages a mapping between reward functions and optimal policies to solve a classification problem on human preference data, resulting in an algorithm that can optimize the reward function exactly with a single stage of policy training.
The authors conducted experiments where they claim DPO can fine-tune language models with human preferences as well or better than existing algorithms while matching or exceeding the ability of reinforcement learning from human feedback (RLHF) methods in controlling sentiment and improving response quality.
Challenges and Open Opportunities in Instruction Tuning: The Case Study of AYA – Invited Talk by Sara Hooker
In an invited talk at the Instruction Tuning and Instruction Following Workshop, Sara Hooker shared insights and open questions inspired by AYA, a year-long open science project aimed at building a multilingual language model via instruction tuning. AYA brought together researchers, engineers, linguists, social scientists, and lifelong learners from over 100 countries to contribute to improving the coverage of instruction fine tuned datasets for 101 languages. The project was initiated by Cohere For AI as a collaborative effort with various institutions.


The speaker used the AYA project as a basis to discuss broader research directions concerning instruction finetuning optimization approaches. The most illuminating parts of the talk were the emphasis on how differently resourced various languages are, and the challenges around evaluating multilingual outputs from language models.
Acknowledgment: All of the papers and content above are adapted from the papers/talks themselves (hyperlinked to the original where appropriate), as well as the OpenReview pages for the various papers. Our thanks and gratitude to the authors, as well as OpenReview and the NeurIPS conference.