
Bias can creep into algorithms and data in many different ways. The key is “ethics by design”, and the only way to make sure your program doesn’t harm users is to make the AI ethical from day one. Bias can be pre-existing (conscious or subconscious), technical, or emergent. You need to be mindful at every stage of development to avoid bias and objectively check your training data.
The delicate balance of trust in Conversation AI
Businesses and governments are enthusiastic about the potential of AI and it falls right at the heart of the current tech boom. But the flip side is that AI also makes many consumers anxious because they don’t trust the technology.
Arguably, AI will have such a profound effect on us all, that YOU (AI developers) are representatives of future humanity and so you have an ethical obligation to be transparent in your efforts. No pressure!
Why are ethics important in AI?
Conversation Intelligence (CI) relies on two things: algorithms and data.
Bias can creep into algorithms in many ways. An algorithm may be skewed to achieve a particular outcome – for example, towards greater caution in offering loans to a certain group of people, or prioritizing those with higher “social credit” scores. The personal bias of developers (be it conscious or unconscious) can creep in when writing the algorithms too. In CI, problems can arise from the “text corpus” — the source material the algorithm uses.
Machines that learn from biased data will make biased decisions. For example, when Amazon’s AI hiring system learned to give female candidates a lower score than male candidates. Or when an AI allocated a higher standard of healthcare to white patients in the U.S.
Unfortunately, most code is only decipherable by the developers who wrote it, making it difficult for even technical people to understand, let alone end users. This means even open-source code is not transparent. The key is “ethics by design”; in other words, it’s now on you as a developer, and your team, to make sure your program doesn’t harm users. And the only way to make sure it doesn’t is to make the AI ethical from day one.
What constitutes bias?
To identify bias you need to understand what it is. There are three categories of bias in computer systems:
- Pre-existing bias comes from underlying social institutions, practices, and attitudes. These can create personal biases within developers, which can be explicit and conscious, or implicit and unconscious. The same is true of input data which, if poorly selected or from a biased source, will influence the outcomes created by your CI system. For example, the bias can already be present in the training data itself, or a text classification problem might be biased towards one specific type of variant or sentiment. For example, gender stereotypes, when you label a doctor as a man and the system then concludes that a nurse is a woman.
- Technical bias arises from technical constraints, like constraints on your program, its design, or some other system limitation. For example, if a flight path algorithm sorts by alphabetical order it’ll be biased in favor of American Airlines over United Airlines; if a search engine shows only three results per screen there’ll be a bias towards the top three results; and if software relies on random results, bias will arise if the number generator isn’t truly random.
- Emergent bias happens when algorithms apply knowledge from old contexts to new ones, without considering changes in societal knowledge or cultural values. This can happen when:
- Training data doesn’t align with your algorithms’ real-world contexts
- Unpredictable correlations emerge when large data sets are compared to each other.
- Data collected about web-browsing patterns align with data marked as sensitive (e.g. relating to race or sexual orientation) and this can lead to discrimination.
- An algorithm draws conclusions from correlations, without being able to understand them.
When data collected for an algorithm results in real-world responses which are fed back into the algorithm (known as a feedback loop) this can introduce or compound (emergent) bias. An example of this is the COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) algorithm used by Judges to predict risks of granting bail. Defendants’ reoffending risk score was found to be biased against African-Americans, as compared to white defendants who were equally likely to reoffend, resulting in longer periods of detention while awaiting trial.
How to test your model for bias
You need to be mindful at every stage of building to avoid bias by design, and check your training data for pre-existing bias or bias that could emerge.
For example, with the risk-predicting bail system, you could remove the column of data that refers to race so that the system focuses on other factors, like location and age.
Of course, the more data you have the bigger the issue to resolve.
Ethics failures in conversation data are much less common than, for example, with GPT3 and BERT. These are both huge models trained on data from the internet (for example the majority for GPT3 comes from Common Crawl, as well as other sources) which can enforce gender and racial stereotypes. You would deal with this by making changes when you pre-process the data. You clean it and remove the stereotyped comments so that they’re not reinforced when the data goes into the model.
If you use an API to build, it will lack data, but this provides you with the opportunity to introduce training data from the big models, that already understand semantics, that you can then fine tune in your model for the specific task you need.
You must test your own application for bias. How you do this depends on the use case:
- If it’s text classification then you fool the model by replacing random entities or genders.
- If it’s image classification you can blur the image or add another.
- You can simulate a training/testing mismatch, so if you have a text classification task on sentiment you can apply the same to an action items classification model.
- You could blind the algorithm to sensitive attributes, but do this with caution as blinding the algorithm to sensitive attributes can cause algorithmic bias in some situations.
- You can also train with a domain shift, where you train your model in business-specific jargon, and then use the model on, say, a call center conversation. This will create a shift, as part of the training, to expand your system’s data and understanding. To evaluate the risk of bias, you can send slight variations of each data point and see if your model can generalize.
- You can use bias checking tools like AI Fairness 360, Watson OpenScale, and What-If Tool to detect and mitigate bias.
Bias testing lifecycle
At Symbl.ai we have a tried and tested lifecycle to help our developers to identify bias. You can implement everything above by following the steps below to ensure a robust process.
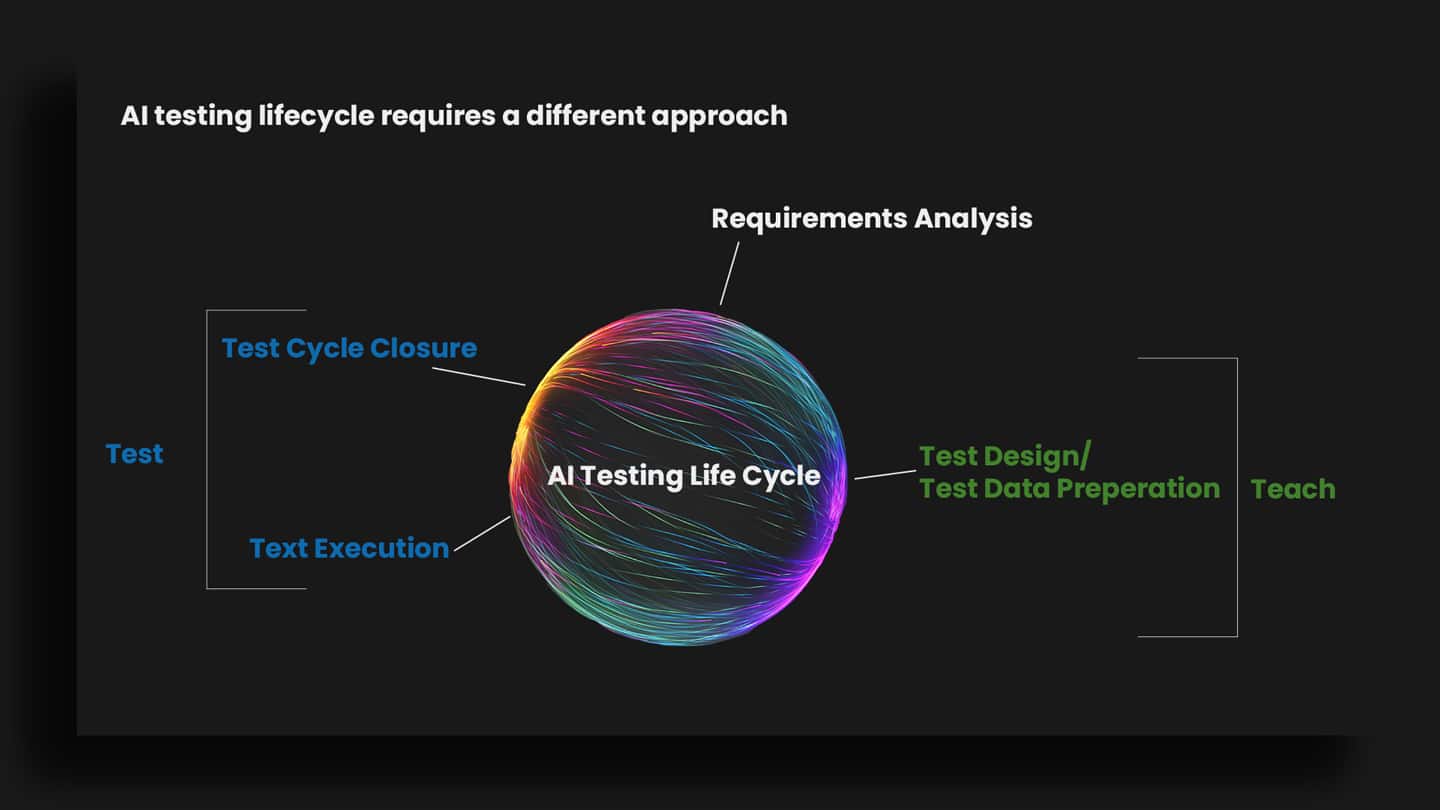
- Requirements Analysis – This is the stage where you figure out what or where potential bias could be in your model.
- Test Design, Test Data, Preparation – Here you need to find data points to break the model. You’ll undertake data aggregation, labeling and experiences.
You labelling the data is key to this preparation stage in your model. The model learns from these labels. This where bias can creep in because some items can be subjective, for example, while one individual may label a certain word or phrase, another may not. Your method of approaching labeling will reduce bias in this data preparation stage.
It’s a good idea to give the data to five different people, rather than just have one person’s perspective, and for them all to label the same data and take the common ones from there. If you use diverse teams and test on diverse groups then you can avoid unsettling outcomes that magnify hidden prejudices.
If you’re using your own data, you can prepare it. But in most situations you’ll receive data from a third party. In this situation you have to fool the system as explained above. This is a fine-tuning step which will alter the explanations without hurting the accuracy of your original model.
- Test Execution – This is the part where you actually hit the model with the bias-heavy testing dataset that you’ve prepared. The results from this step are the ones for you to scrutinize, in order to gauge the effect of any bias that might have crept in.
- Test Cycle Close – The point at which you close the test cycle is a matter of judgment. The next section below, “When have you done enough?”, for more actionable advice on this.
- Auditing – As a step of best practice, after the test cycle has been closed you should undertake continued formal and regular auditing of the algorithms. Here you can review both input data and output decisions to provide insight into the algorithms’ behaviour.
When have you done enough?
“Testing AI systems presents a completely new set of challenges. While traditional application testing is deterministic, with a finite number of scenarios that can be defined in advance, AI systems require a limitless approach to testing,” – Kishore Durg, senior MD, Growth and Strategy and Global Testing Services Lead for Accenture.
A ‘limitless approach’ is quite an intimidating prospect! But remember, bias can’t be completely eliminated. Your job to minimize the effect of bias as much as possible.
The extent to which you need to test and clean and train depends on the size of your training data. You may need to test 100-200 instances of each potential bias to be sure it has not crept into your model.
If you have bad results from your bias testing, you know your model isn’t working properly for certain types of bias. Try segmenting the different types of bias. Then you’ll need to make changes in the data preprocessing phase (like masking gender/race related info, if the bias is indeed related to genders/race). Once you’ve done that you need to retest for all the biases you identified earlier, and then validate the results to evaluate whether the biases have been mitigated. If not, the cycle repeats until you end up with a tolerably small error rate.
Learn more about the ethical approach of Symbl.ai.
Further reading:
- Developers, it’s time to brush up on your philosophy: Ethical AI is the new big thing in tech
- Inside the Digital Society: Why do we need ethics in AI?
- AI and Empathy: Combining artificial intelligence with human ethics for better engagement
- 5 Examples of Biased Artificial Intelligence
- Algorithmic bias detection and mitigation: Best practices and policies to reduce consumer harms