
Introduction
Large Language Models (LLMs) have revolutionized natural language processing, demonstrating impressive capabilities in sentiment analysis and emotion detection. However, the way most LLMs learn and interpret language differs significantly from human language acquisition. This discrepancy raises an important question: do LLMs trained with multimodal features and across different forms of data, such as conversation and text, effectively utilize those features when processing data from a single modality? To answer this, we set up experiments to compare general LLMs against LLMs that are specialized on multimodal data. Specifically, we compare the Llama-2-70B general model against a version of that model which is fine tuned on human conversation data (Llama-2-70B-conversation).
Human communication and conversation is inherently multimodal, involving both verbal and non-verbal cues. We learn to interpret conversational communication first, including intonation and modulation, and then transfer those skills to written communication. Additionally, the conversation modality encodes distinct differences from other text data, such as turn-taking, context dependency, dialog and speech acts, real-time interaction etc. The question of whether the skills needed to excel at different modalities (text vs. conversation) are transferable across those modalities is what we aim to explore in our new research paper, currently under submission at the Association for Computational Linguistics’ rolling review cycle.
To test our hypothesis, we pick one of the most challenging use cases in conversation understanding and NLP in general: deceptive communication. This includes sarcasm, irony, and condescension, and serves as an illustrating test case for multimodal feature transfer. These forms of covert deception are challenging to detect in text representations of media, as they often rely on multi-turn modulation and prosody changes that are absent in just plain text data.
At Symbl.ai, our animating purpose has been to investigate the nuances and complexities that make human conversation distinct from the mere processing of text data on the web. This line of work extends those investigations by examining whether there are inherent features in conversational data that can be utilized by LLMs to better detect and understand one of the most complex human conversational behaviors – deceptive communication.
Motivation
The motivation for this research stems from the observation that LLMs, until recently, primarily learned language through vast amounts of text-only data on the web. While this approach has yielded impressive results, it fails to capture the inherently multimodal nature of human communication.
The ability to detect deceptive communication is a complex task for both humans and machines, especially in the text-only modality. We focus on this specific aspect of communication to evaluate the multimodal transfer of skills in LLMs. By comparing the performance of multimodal models (conversation+text) with unimodal models, we aim to gain insights into how LLMs interpret and utilize multimodal features.
Results
Our experiments involved comparing the performance of two types of models: text-only models, and text models trained with a special emphasis on human-to-human conversations. These models are exemplified respectively in our current work by the Llama-2-70B model – a very popular openly available LLM; and a fine tuned version of that LLM which specializes in conversational data. We also varied the prompting approach, using both basic prompts and prompts designed to emphasize the model’s conversational features.
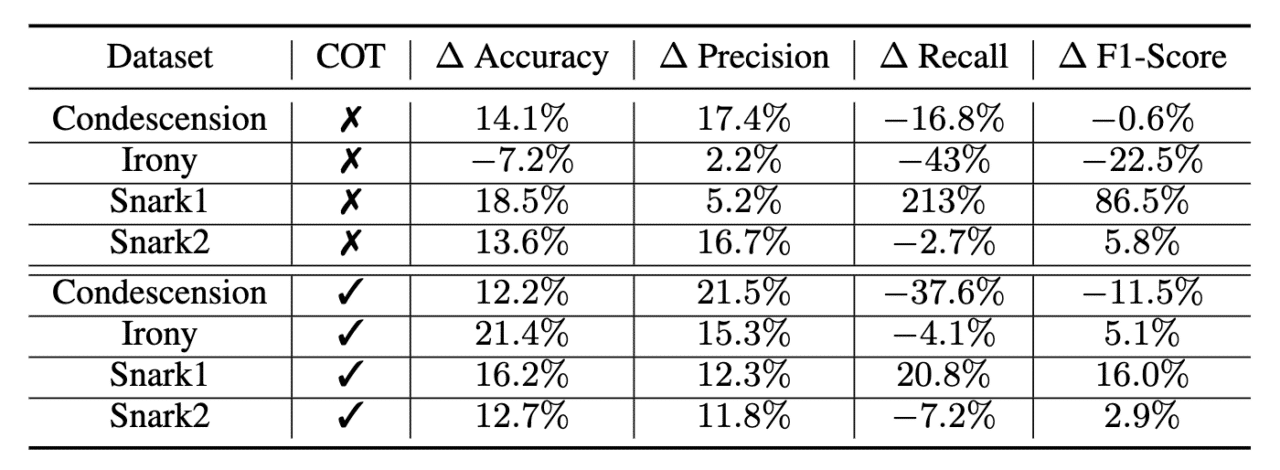
The results, presented in Tables 1 and 2, offer valuable insights into multimodal feature transfer in LLMs. Table 1 highlights the advantage of using conversation+text models over unimodal text models for identifying deceptive communication such as snark, irony, and condescension. The Llama-2-70B-conversation model achieves higher accuracy and precision in identifying such deceptive communication, with impressive improvements in accuracy and F1-score. This supports our central hypothesis that adding the additional features that come from the conversation modality improves the performance of the language model on challenging use cases and data.
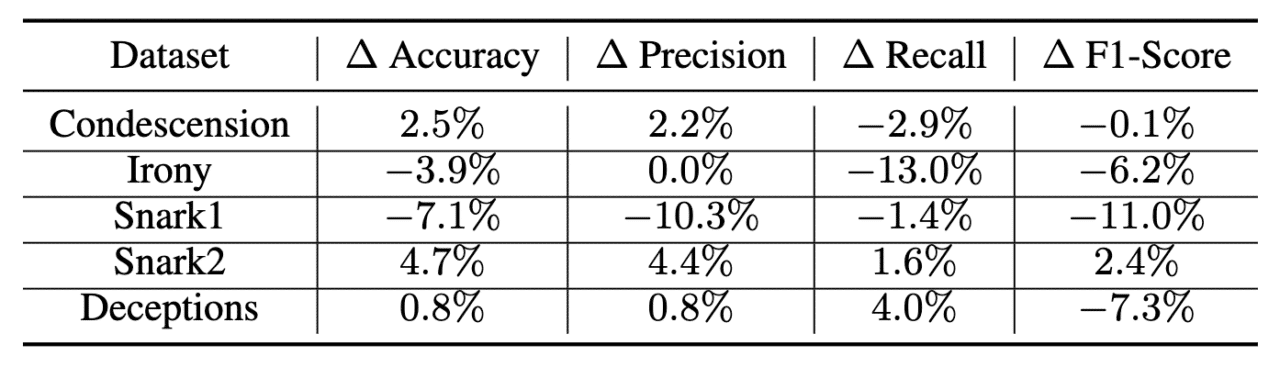
Table 2 reveals the impact of changes in prompting techniques. Emphasizing conversational features in prompts yields mixed results, with a slight improvement in accuracy and precision but a decline in recall. This suggests that while the model may better identify deceptive communication correctly when it is guided to pay special attention to features from the conversation modality via the input prompt, this sharpened focus may also cause it to miss more instances of such communication from an overall set.
Conclusion
Our findings suggest that the phenomenon of multimodal feature transfer occurs in LLMs, as conversation-tuned models outperform unimodal models in deceptive communication detection – a traditionally challenging use case for language models. Additionally, prompts emphasizing speech and conversation features can enhance performance in certain cases.
These results have important implications for future research and applications, indicating that models are capable of transferring what they learned on multimodal data to single-modality data, improving LLM performance on specific tasks that may require multimodal training. We are currently further investigating the effect of other modalities associated with human conversation data on the feature transfer phenomenon in LLMs, and on the overall accuracy of tasks that are challenging to today’s large language models.