
Open source speech recognition demands more work on your part specifically with data collection, but is customizable and often available for free. With popular speech recognition APIs, you don’t have to worry about building and fine tuning with your data, but your ability to customize will be limited.
Building speech recognition into your application
When integrating speech recognition into any app, you have two main options: open source tools or “done-for-you” APIs.
Open source speech recognition models
There’s always a catch when something’s free. While there are several open source speech recognition models available, they will take more work on your part specifically on data aggregation than their API based alternatives.
Some developer toolkits are easy to customize to fit your needs perfectly, and all of them will let you create offline speech recognition to work with locally hosted data. You get to define your own level of security and privacy in your application without worrying about future expenses for this part of your solution.
Pros:
+ Customizable
+ Possibly free
+ Can be used to run both online and offline deployment
Cons:
– You have to train with your data
– And fine tune, maintain
– And make sure it’s deployed securely.
APIs for speech recognition
These come ready to use but at a cost. While you have data traffic from your application to a server and back, the API ships this data in small, secure packets. You don’t need to build and maintain the solution.
Pros:
+ No coding
+ Security and updates are all taken care of
+ Fast, easy to get working speech recognition in your application
Cons:
– Rarely free
– Don’t offer the opportunity of customization
– Don’t work well for languages with small amounts of available data like the endangered or extinct languages recorded on UNESCO’s
language atlas
Popular open source options and what sets them apart
If you’re working with a spoken language with a very small amount of available data, your best bet is to customize an open source speaker recognition model to fit your needs.
One interesting use case for open source speech recognition is preserving endangered languages for the future. Let’s say you’re building an application that helps the Northern Paiute people (currently estimated to consist of around 300 individuals) use their native language to search the web or make notes while offline. These are the most tried, tested, and trusted models you can use:
Project DeepSpeech (also known as Mozilla Voice STT): Mozilla Voice STT has an English speech recognition model that’s proven relatively easy to adjust to other languages. In just two months, Silicon Valley AI Lab got the system to work on Mandarin Chinese. The tool is available in several programming languages and easy to adjust to other alphabets. So, DeepSpeech would be your best bet for building a speaker diarization model for languages other than English.
Plus, Project DeepSpeech uses the open source AI library TensorFlow to build speech recognition models. The library works so well that DeepSpeech has been used in projects across the globe and is currently a key ingredient in the Papa Reo project, which helps New Zealanders engage with voice assistants in their own languages.
Deepspeech can also be used with Mozilla’s Common Voice dataset to train voice-enabled applications with an ever-growing number of languages, including even those with relatively small speaker populations.
You can find everything you need to get starting with DeepSpeech on Mozilla’s GitHub Deepspeech wiki.
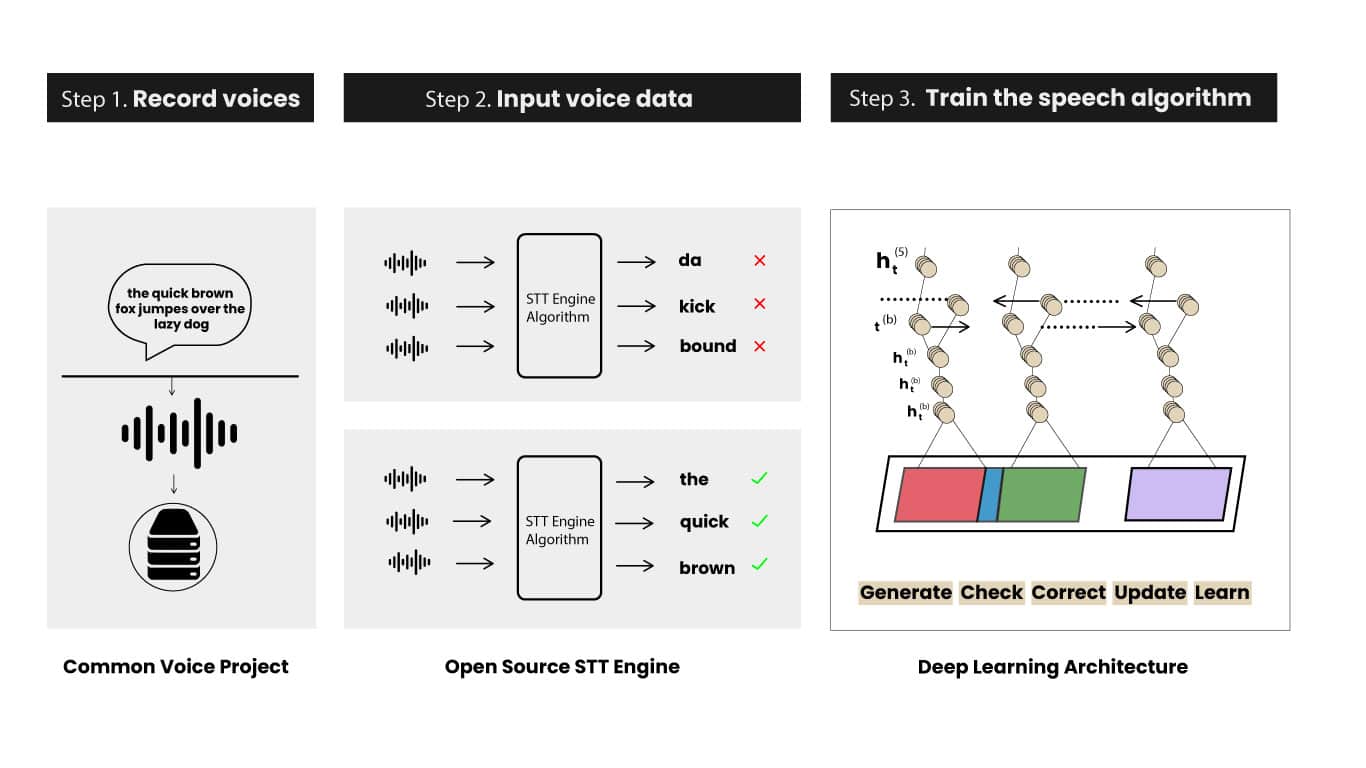
How a speech application learns (Mozilla Research)
CMUSphinx: CMUSphinx is a widely known toolkit designed to handle the issues of speaker recognition in languages with small amounts of available data. The speech recognition library is lightweight, and the toolkit has a very adjustable speech recognizer written in C++.
Pocketsphinx, which is part of the CMUSphinx toolkit, is written in C and offers a lightweight speech recognition engine that works particularly well with handheld and mobile devices. It’s easy to install and set up, but said to have issues with low quality audio.
If you want to use CMUSphinx, you’ll find an active forum of developers on Github, Reddit and Telegram for support.
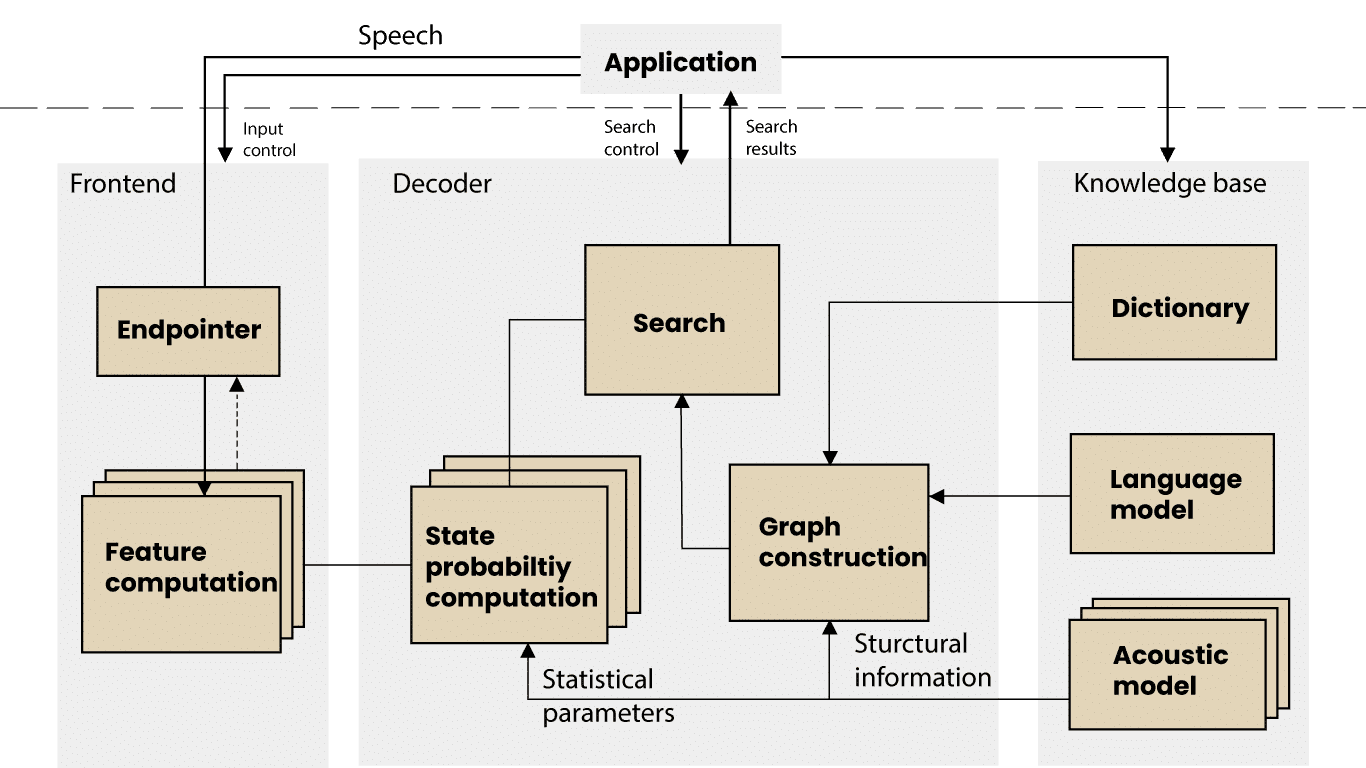
CMU Sphinx design architecture (Lamere et. al, 2003)
Kaldi: Kaldi is written in C++, licensed under the Apache License v2.0, and has been thoroughly tested in speech recognition research since 2011. The Kaldi ASR is an open source speech recognition tool that runs on Linux and is designed to be easy to modify for your purposes.
Kaldi benefits developers with generic algorithms and easy-to-reuse code. The tool comes with three free datasets for you to start training your machine learning algorithms on.
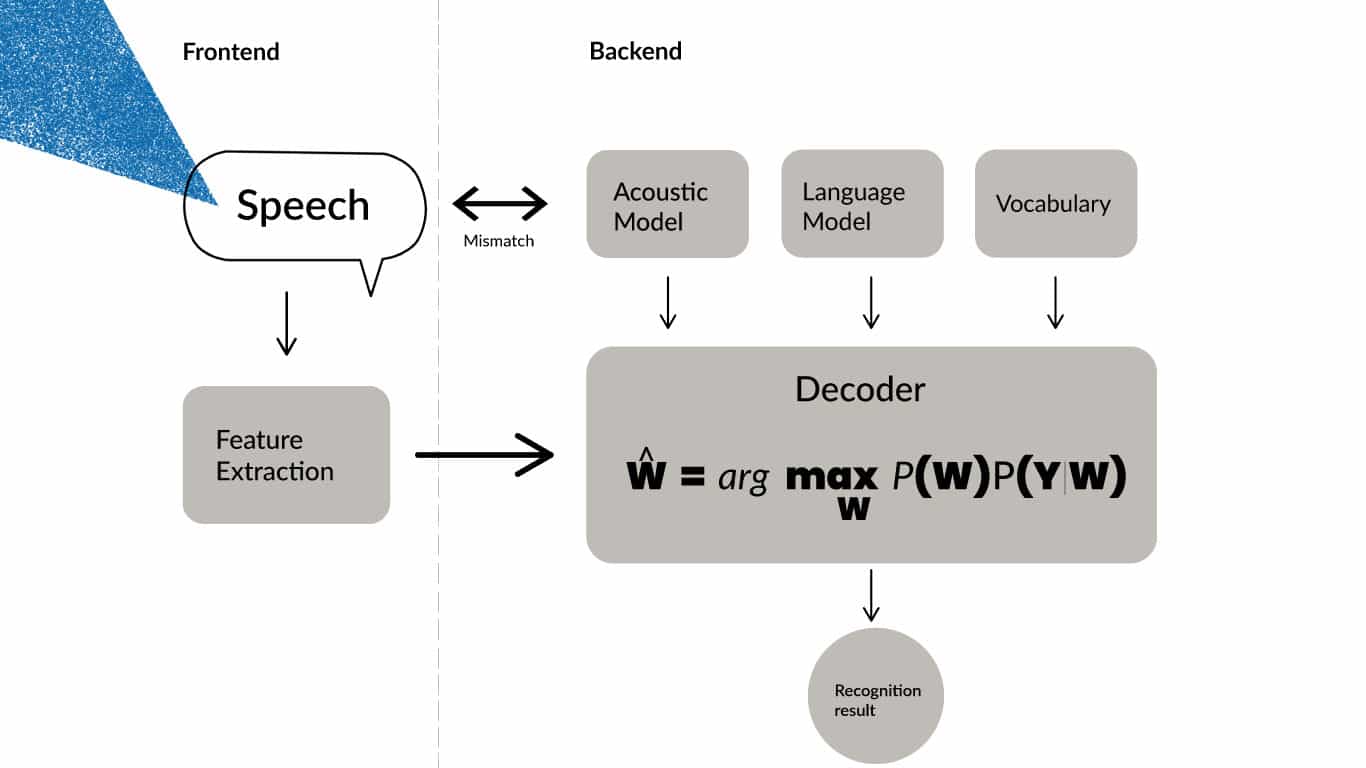
Diagram of Kaldi architecture.
Wav2Letter++ (by Facebook): Wav2Letter++ is written exclusively in C++ (as you may have already guessed) and is said to be the fastest open source speech recognition system.
This end-to-end ASR toolkit is very similar to DeepSpeech, so if you’re building a model for a small language, this could also be good option. Wav2Letter++ comes with a Python API that makes it easy for you to take advantage of the large libraries in your own Python code through Python bindings.
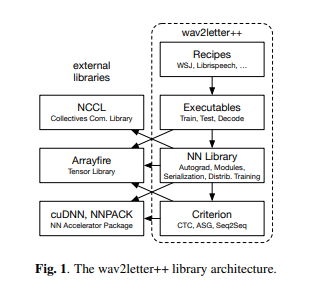
Wav2letter++ library and architecture (Source: Pratap, V. et al., 2018)
Alizé: Alizé provides the basic operations required for handling configuration files and features, matrix operations, error handling, etc. It has several layers in its architecture: a low-level library for use of Gaussian mixture models, a high-level functionality for model training, speaker diarization, data manipulation, and more. It even has a Java API for use in Android applications.
You can find support for Alizé on GitHub and in a LinkedIn group maintained by the University of Avignon in France.
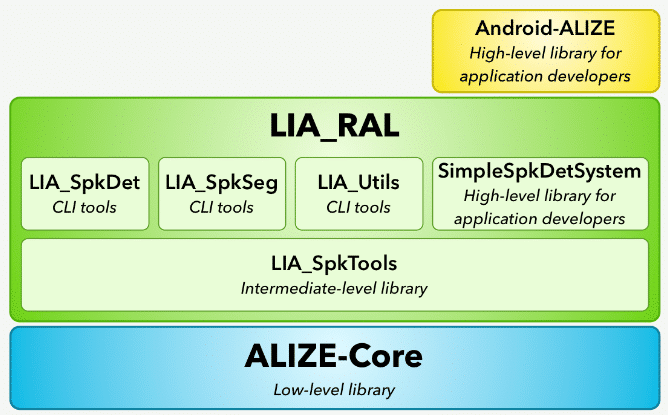
Basic architecture of Alizé (Source: University of Avignon).
Popular APIs for speech recognition
For an effective speech recognition API that you can quickly build into your application, check out these APIs.
Google Speech-to-Text: Google Speech-to-Text API has four different machine learning models, each one pre-trained and named for the purpose it serves:
The first two APIs transcribe audio. “ASR: Command and search” is made to capture short clips (like voice search) or commands directed at a voice assistant, Smart TV, or another IOT device. Finally, “ASR: Default” is made for offline transcription of longer monologues, like medical transcriptions.
When using Google’s API you benefit from the enormous amount of voice and video data that Google has gathered over the years. This data has helped to ensure a very low error rate and provide the ability to automatically recognize more than 125 languages.
However, the advanced video and phone call APIs have a larger price tag and currently only support versions of English, Mandarin Chinese and Japanese. If you want to customize your API, this might not be your best choice, since Google Speech-to-Text only lets you add specific terms and phrases relevant to your task.
Symbl Conversation API: When speaking of APIs for speech recognition, we can’t ignore our very own Symbl Conversation API. You can use our APIs with minimal technical know-how and pair it with any programming language.
Symbl’s comprehensive suite of APIs can be integrated directly over telephony, real-time audio streams, and audio recordings – saving you the time of building your own real-time infrastructure. Plus, Symbl improves the accuracy of transcription by adding context understanding and enabling you to surface AI-powered insights – all out of the box.
We also have an active developer community on Slack where you can go to learn more, get support, and let us know what you’d like to see in our future releases.
Other popular APIs to consider for your speaker recognition include:
-
- AWS Transcribe by Amazon
- Speech to Text by Microsoft Azure
- Rev.ai
- Deepgram
- Speechmatics
Additional reading
You can find more info on the solutions mentioned here and likely stumble upon even more at these links:
- Symbl’s Conversation API
- Automatic Speech Recognition (ASR) Evaluation
- Fully Supervised Speaker Diarization
- Accurate Online Speaker Diarization with Supervised Learning
- 10 Good Open Source Speech Recognition Systems
- How to start with Kaldi and speech recognition