
In the rapidly evolving field of artificial intelligence (AI), large language models (LLMs) have exhibited remarkable capabilities across a broad spectrum of tasks in a very short time. These models’ capabilities have taken the world by storm, resulting in large-scale investment into the training and deployment of proprietary and open-source models. However, one nagging question remains: Do these models perform equally well across all types of data and domains? This question becomes particularly relevant when considering the domain of human-human interactions.
Human-Human Interactions (Conversations)
Human conversations are at the heart of human language and communication. They are distinguished by their complexity and depth. Any progress on language models should reflect concordant progress in handling human conversations.
Unlike other data types, human conversations are distinguished by several key characteristics:
- Interactivity: The reciprocal and dynamic nature of human conversations makes them highly interactive, with participants actively responding to and building upon each other’s contributions.
- Contextuality: Most conversations are deeply embedded in specific shared contexts, which may include physical surroundings, relationships, cultural backgrounds, shared history etc.
- Adaptability: Participants in a conversation typically adjust and adapt their speech and content to immediate and real-time feedback from the other participant(s).
- Emotional & Psychological States: At their most detailed, conversations convey more than just factual information: they also act as a transfer medium for emotional and psychological states, through tone, pace, volume, emotion, choice of words, etc.
These attributes highlight the rich, multifaceted nature of human conversations, presenting a unique challenge for LLMs.
Domain Representation in LLM Datasets
Today’s LLMs are trained on vast amounts of data – well north of 1 trillion tokens – across different domains and data distributions. However, a model is only as good as the data that it has seen: to understand how well the model understands human conversations, investigating the composition of the model’s training data is crucial. Despite the vast amounts of data fed into LLMs, a closer inspection reveals a disproportionate under-representation of human conversation data. Utilizing the Common Crawl dataset, a foundational source for many LLM training corpora representing data on the internet, our analysis uncovers that human conversations constitute a mere 0.0085% of LLM training data.
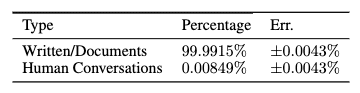
This shows that human conversation data on the web is underrepresented, and that this is a resource-poor domain. This lopsided representation leads to several artifacts that hamper a model’s ability to effectively and accurately attend to data and contexts from such underrepresented (and important) domains.
Quantitative Analysis of Data Domains
In order to analyze how a language model treats human-human conversations as compared to data from other domains we employ a set of three metrics aimed at dissecting language models’ attention – the mechanism LLMs use to model contextual associations. These metrics jointly seek to provide an empirical overview of the work that a model undertakes when navigating different data domains. Our analysis spans four domains – human-human conversations, web data, code, and mathematics.
Attention Distance Difference
This metric highlights the difference in the distance between the attention spans across tokens between a pair of domains: that is, how a model needs to adapt its attention span when switching from data in one domain to the other. The full details of how this metric is calculated can be found in the paper.
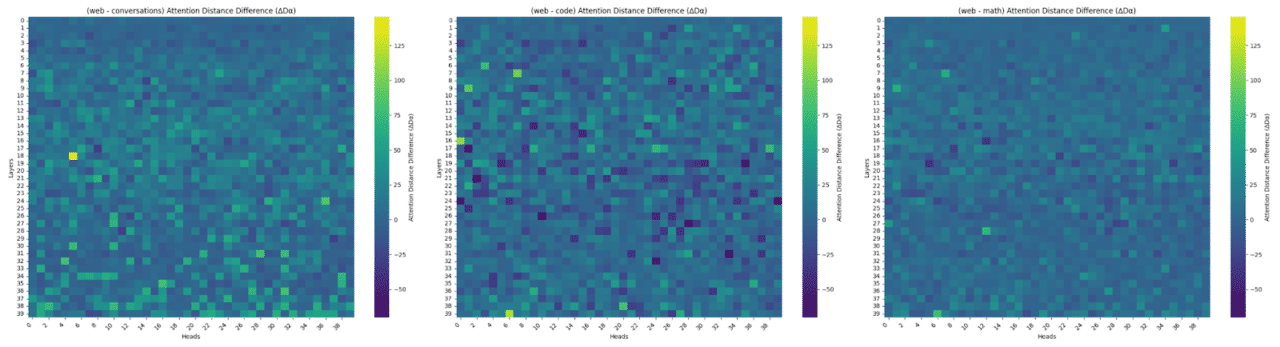
Differences in attention distances when comparing general web data against 3 data domains: human conversations (left), code (middle), and math (right). Higher distance indicates longer contextual dependencies.
Human-human conversations demand significantly longer attention distances compared to web content, as well as code and math data, indicating that more robust modeling of longer-term contextual relationships by models is necessary. This can be seen when comparing to the middle attention chart (featuring code data), where higher attention distances are observed in the initial half of the layers, while there is a reduction as we head into the deeper layers – suggesting that the model’s attention is able to become more localized and focus on closer contextual relationships.
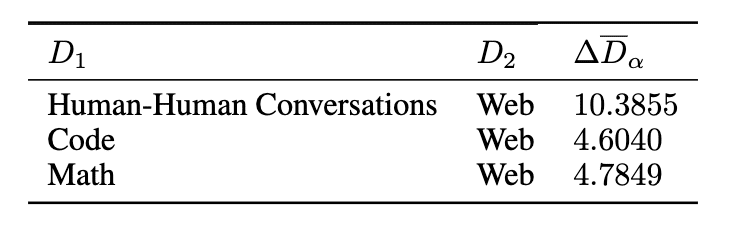
Average attention distance difference across domains.
Attention Dispersion
We can also calculate the dispersion of the model’s attention across domain data, which indicates whether the model can learn to focus narrowly on just a few telltale keywords and markers, or whether it must spread its attention thin across the entire context. For this calculation, we use the mean attention entropy as a proxy for the model’s attention dispersion, considering the same four domains – web, conversations, code, math – across layers and heads, as below:
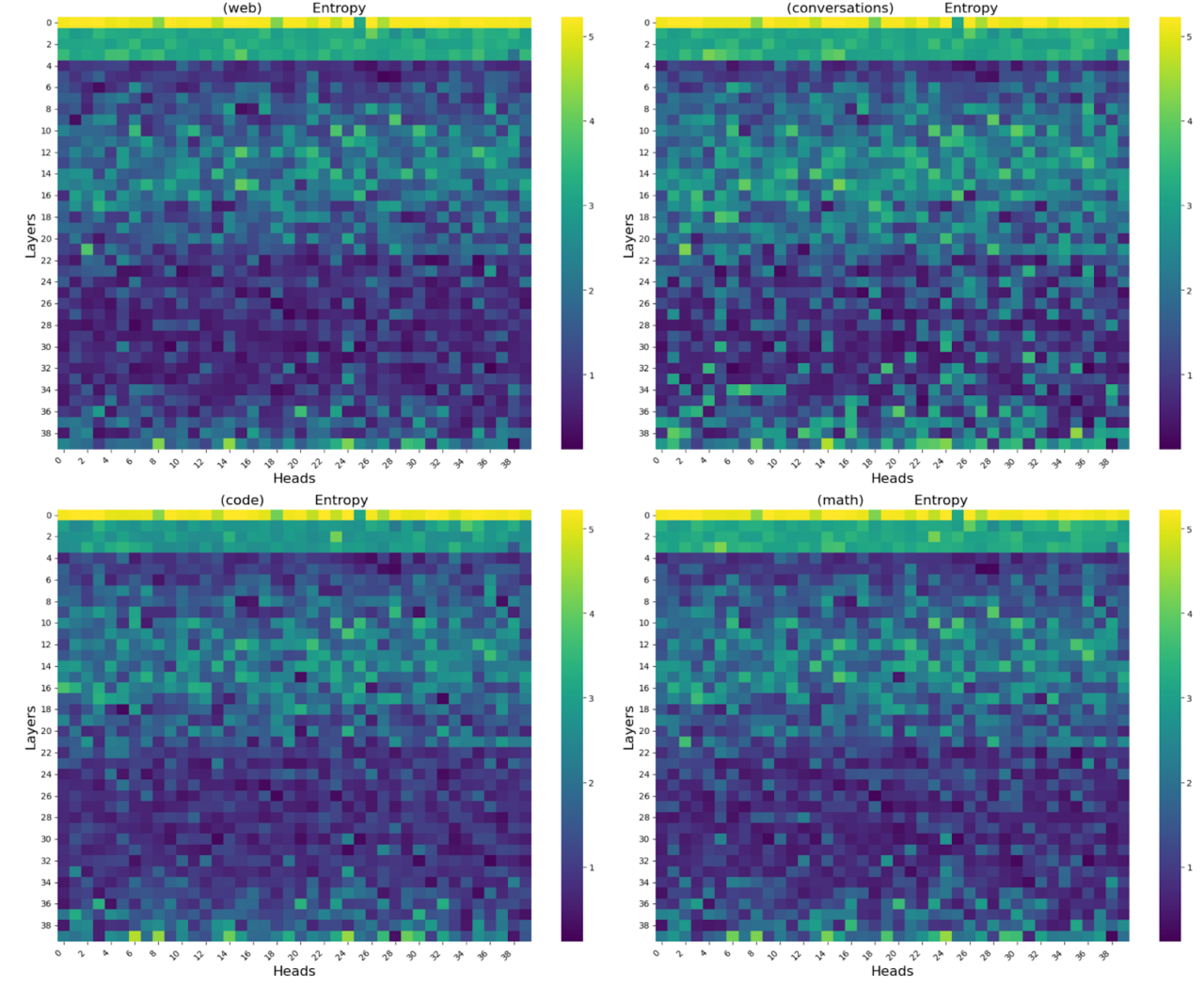
This heatmap shows that there is much higher entropy between layers 22 – 36 for the conversation data, which indicates that the model has to attend strongly to more tokens in this domain than in the others. This indicates a higher complexity for the human conversation domain, leading to higher attention dispersion on the part of the model as it tries to wrap its attention around the complexity of the context.
Qualitative Analysis of Data Domains
In addition to the quantitative results above, we also strive to provide a more quantitative interpretation of our study, to show how human-human conversation data is different from other domains that are better represented in the training corpora of today’s language models.
t-SNE
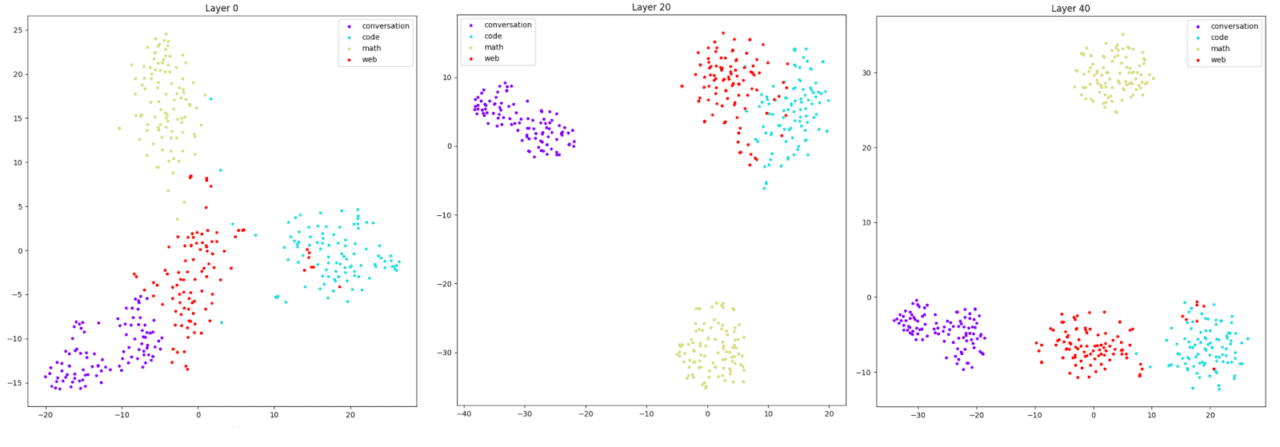
To visualize and understand the representation in the model of various data domains, we use the t-SNE (t-distributed Stochastic Neighbor Embedding) visualization, an unsupervised non-linear dimensionality reduction technique that can be used to represent high-dimensional data by assigning each datapoint to a point in a lower dimension space. We plot these for the first (left), middle (middle), and last (right) layers across the four data domains.
In the first layer, all domains are relatively close to each other, albeit with clear boundaries emerging amongst the clusters. This closer proximity suggests a base level of generic processing before the model adapts to the specific demands of each domain. By the middle layer, human conversations and math data have separated, while web and code still show some overlap. This divergence illustrates the model’s evolving understanding and representation in distinguishing data across domains. In the last layer, there is slightly better separation between web and code domains, while there is still some minimal overlap. This analysis goes to show that models are representing data and contexts from different domains differently.
Example Showing Attention Dispersion
Finally, to demonstrate how the model’s attention differs when attending to content from different domains, we visualize 4 different contexts/data points from each of the domains at the same layer and head.
 |  |
 |  |
Some interesting attention patterns are exhibited in the above. For human conversations (top left), as indicated by all the quantitative metrics, the model must attend to tokens across the entire context, and accommodate longer-term dependencies. For code (top right), by comparison, the model very clearly knows that only specific tokens are important tokens, and that attention must be pooled there: a reflection of the structured and rule-based nature of code data. Web (bottom left) and math (bottom right) data is somewhere in the middle, with the attention not as dense as human conversations, but also more distributed than the code domain.
An LLM for Human Conversations
This analysis distinguishes and separates human conversation data from other data domains, and the unique demands that conversation data places on a model (via a study of attention). The results highlight that human conversations exhibit a unique set of characteristics, necessitating more robust modeling of long-term contextual relationships by any model that hopes to produce high-quality results. The higher attention dispersion (entropy) observed in the human conversation domain suggests a strong need for large language models to adopt a much broader focus to capture the necessary context and nuances required to succeed in such domains.
At Symbl, we have built an LLM specialized for human conversations – Nebula. Nebula is trained with a significant amount of human-human conversation data, and optimized to work best on human conversations. Learn more about using Nebula here.
Read the paper that this article is based on here.