
Speaker diarization is the process of dividing audio into segments belonging to each individual speaker. It helps AI and humans understand who is saying what throughout the conversation.
Speaker diarization – definition and components
Speaker diarization is a method of breaking up captured conversations to identify different speakers and enable businesses to build speech analytics applications. . There are many challenges in capturing human to human conversations, and speaker diarization is one of the important solutions.
By breaking up the audio stream of a conversation into segments corresponding to individual speakers in a conversation, it’s easier for both AI and humans reading a transcript to follow the flow of the conversation.
To perform speaker diarization, algorithms need to be set up for two processes:
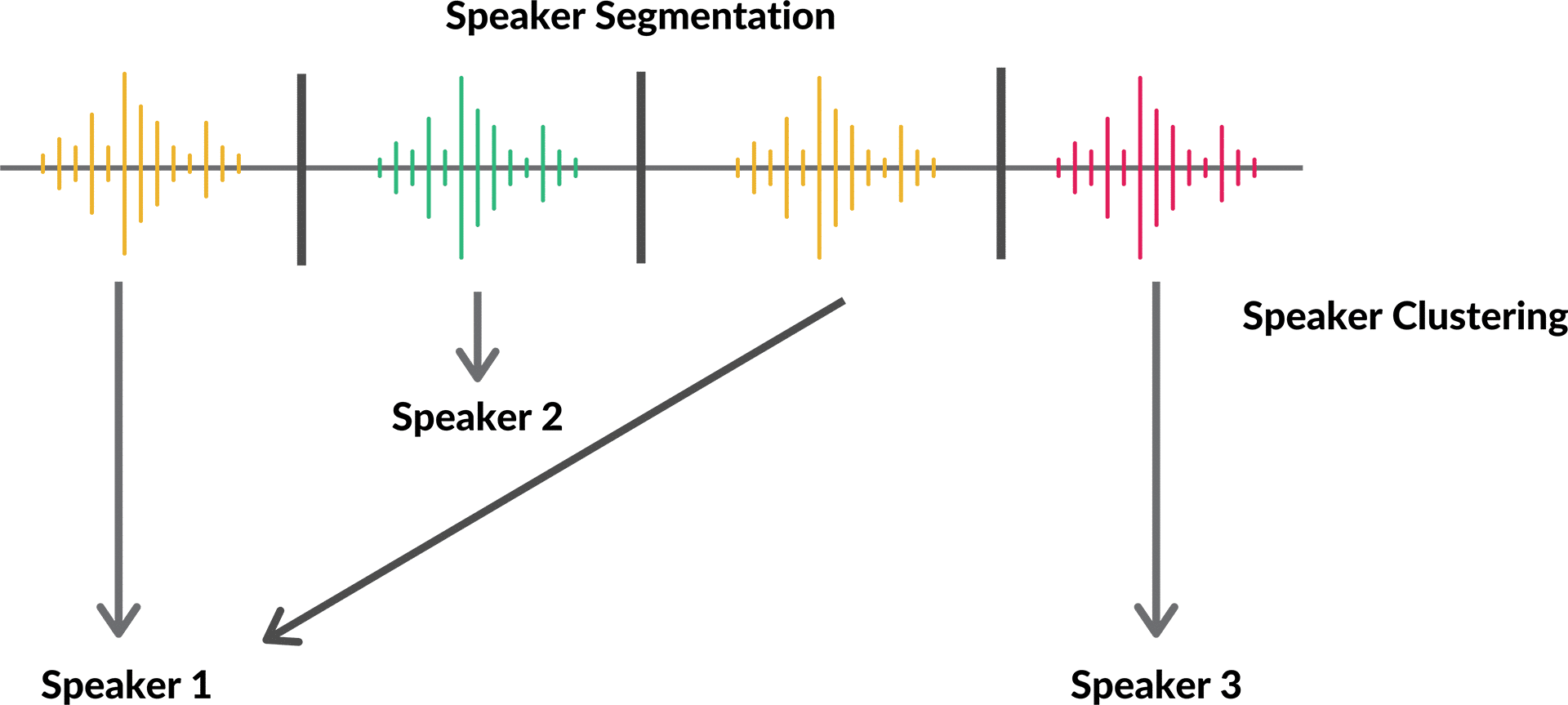
Speaker recognition: Also known as speaker segmentation. This process analyzes features of each voice and the zero-crossing rate to identify who speaks when. Characteristics like pitch are used to identify and typically reveal the gender of each speaker.
Speaker clustering: As the speakers are recognized, they’re put in separate segments leaving out anything but speech, so the entire conversation can be labelled correctly and easily understood. This process uses either a deterministic or probabilistic approach to clarify how many people are participating in the conversation.
Deterministic speaker clustering groups similar audio segments together based on a single metric. This could be a plosive – the constant popping when a certain speaker pronounces a p-sound. It could also be that one speaker’s audio is remarkably more bassy or with too much treble than the rest. The probabilistic approach uses either Gaussian mixture models (GMM) to extract features from speech input or hidden Markov models (HMM) to recognize patterns in vowels and syllables.
When to use speaker diarization?
Speaker diarization is critical in making conversations easy to understand and extract valuable intel from.
When you go to any kind of meeting with your colleagues, speaker diarization will let an audio recording be turned into meaningful notes right after the meeting. If an AI has “attended” other meetings with you – for example by running through your backlog of recordings and transcriptions – speaker diarization lets it decipher the context in new meetings. The AI can then suggest helpful actions, remind you what certain speakers previously said on the same topics or remind you of points you need to touch on before the meeting ends.
Speaker diarization will also let AI break up external conversations like:
- Customer conversations
- Social conversations
- Support calls
- Sales calls
Each conversation is broken into clusters belonging to the individual speakers. During the conversation these clusters can then be compared to previous interactions with the customer. If the AI has access to emails, chat logs or other transcripts, it can suggest questions to ask in real-time so you can give your customers a better experience.
This means you can use speaker diarization to make inferences in real time as well as in batch. Real-time speaker diarization is known as online speaker clustering and is very useful in the above situations. Offline speaker clusters are based on finished conversations available as recordings. This process gives better results than online speaker clustering and improves the performance of real-time clustering.
Speaker diarization with deep learning
Speaker diarization can be done with I-vectors and through deep neural networks. I-vectors are faster to train and are still being used, but typically considered overkill for the task since they burn through too many computing resources.
Deep neural networks have so far proven to be most effective at speaker diarization with a very low Speaker Error Rate (which defines the percentage of a conversation put in the wrong cluster). This makes it the industry favorite.
Since neural networks can be trained with big datasets they are better equipped to handle different accents and factors around the conversation, like background noise. When the neural network is provided with details about the surroundings (i.e. the input microphone or a certain background noise related to each speaker) it makes it easier for the neural network to perform proper speaker diarization and improve the results.
Supervised vs. unsupervised speaker diarization
Machines can either be trained for speaker diarization in a supervised or unsupervised fashion. The supervised approach to speaker diarization involves providing the machine part of the solution to the task at hand. In the case of speaker diarization that would mean that you had already tagged some or all of the individual speakers in parts of the conversation. You also make it easy for yourself to debug while training the machine.
The supervised approach secures you a lower rate of errors in the final transcription and lets you keep the decision framework as a mathematical formula instead of having to save the conversation that your machine was trained on. Supervised training can only take place on offline recordings. The greatest accuracy is achieved through random forest algorithms that build decision trees and cast majority votes over them.
The downsides to supervised speaker diarization training can be that you have to put in a lot of manual labor and any errors on your part risk training your machine to do the wrong kind of work.
In contrast, unsupervised learning lets your machine lose on a completely unlabeled conversation. The machine has to look for hidden patterns on its own. This takes more time for the machine and has higher error rates, but it saves humans hours of work.
If you’d like to try speaker diarization in real time, Symbl makes it easy with its Async API. Our Async API documentation guides you step-by-step on how to integrate the API to serve your product integration. With Symbl, you can either implement Speaker Diarization (Speaker Separation) with our Async Audio APIs or with our Async Video APIs. Check out the documentation here!
Additional reading:
- Speaker Diarization: A Review of Recent Research
- Speaker Segmentation and Clustering
- Accurate Online Speaker Diarization with Supervised Learning
- Random Forest Algorithm: A Complete Guide
- Speaker diarization using deep neural network embeddings