
The speech-to-noise ratio (SNR) is a measure of unwanted noise in an audio stream relative to recognizable speech. The SNR can negatively affect system performance by limiting operating range or affecting receiver sensitivity. Understanding how to calculate and manage this will help you create a robust, accurate system for real-life situations.
What is speech-to-noise ratio?
The speech-to-noise ratio (SNR) measures the percentage of unwanted noise in an audio stream relative to recognizable speech. This means that the ability to hear and understand speech when there’s background noise is dependent on the SNR.
SNR is an inconvenient feature because of its impact on system performance, like limiting its operating range or affecting the receivers’ sensitivity. It’s random and unpredictable, with no pattern, constant frequency, or amplitude. You can take several measures to reduce SNR, but you can’t eliminate it completely.

An example of speech-to-noise ratio
Let’s assume two people are having a conversation when really loud construction work begins nearby. The construction work noise is 50dB, making the conversation difficult to hear.
If one person is whispering at 30dB, it’ll be hard for the other person to hear them. However, if the other person shouts at 80dB, their voice would be louder than the 50dB produced by the construction work, and both people would hear each other.
So in this case, if:
Shouting = speech (80DdB)
Construction work = noise (50dB)
then:
SNR = 30dB.
How to calculate the speech-to-noise ratio
To assess and then optimize the SNR you need to be able to calculate what it is. As both speech and noise signals are random and change their statistical parameters over time, it is difficult to find a single mathematical formula abstracting the classification between them. That said, here’s a good one from the International Computer Science Institute (ICSI) in Berkeley, California:
SNR_dB = 20.log10(S_rms / N_rms)
whereS_rms is the root-mean square of the speech signal (without any noise present) i.e.sqrt(1/N*sum(s[n]^2)), andN_rms is the root-mean square level of the noise without speech.
This is equal to:
SNR_dB = 10.log10(S_e / N_e)
whereS_e is the total energy of the speech i.e.sum(s[n]^2) etc. — theglobal SNR.
This source is an FAQ, and it goes on to explain why SNR is tricky to calculate due to the non uniform nature of the speech and the solution of finding a definition for speech SNR that does not vary when silence is added to the noise. The actual level of noise added to achieve a given global SNR depends on the amount of padding added to (or, in general, silence present in) the speech example. If you don’t take into account this ambiguity then confusion will reign! The shape of the noise spectrum also plays havoc on the calculations too. For a deep dive on the calculation, there is a detailed technical paper within the source which makes for very interesting reading.
You can also calculate SNR from a single stream of audio. In this scenario you won’t have access to speech and noise signals separately and so you have to estimate the noise in the time and frequency domains of the channel.
What types of noise impact SNR and system performance?
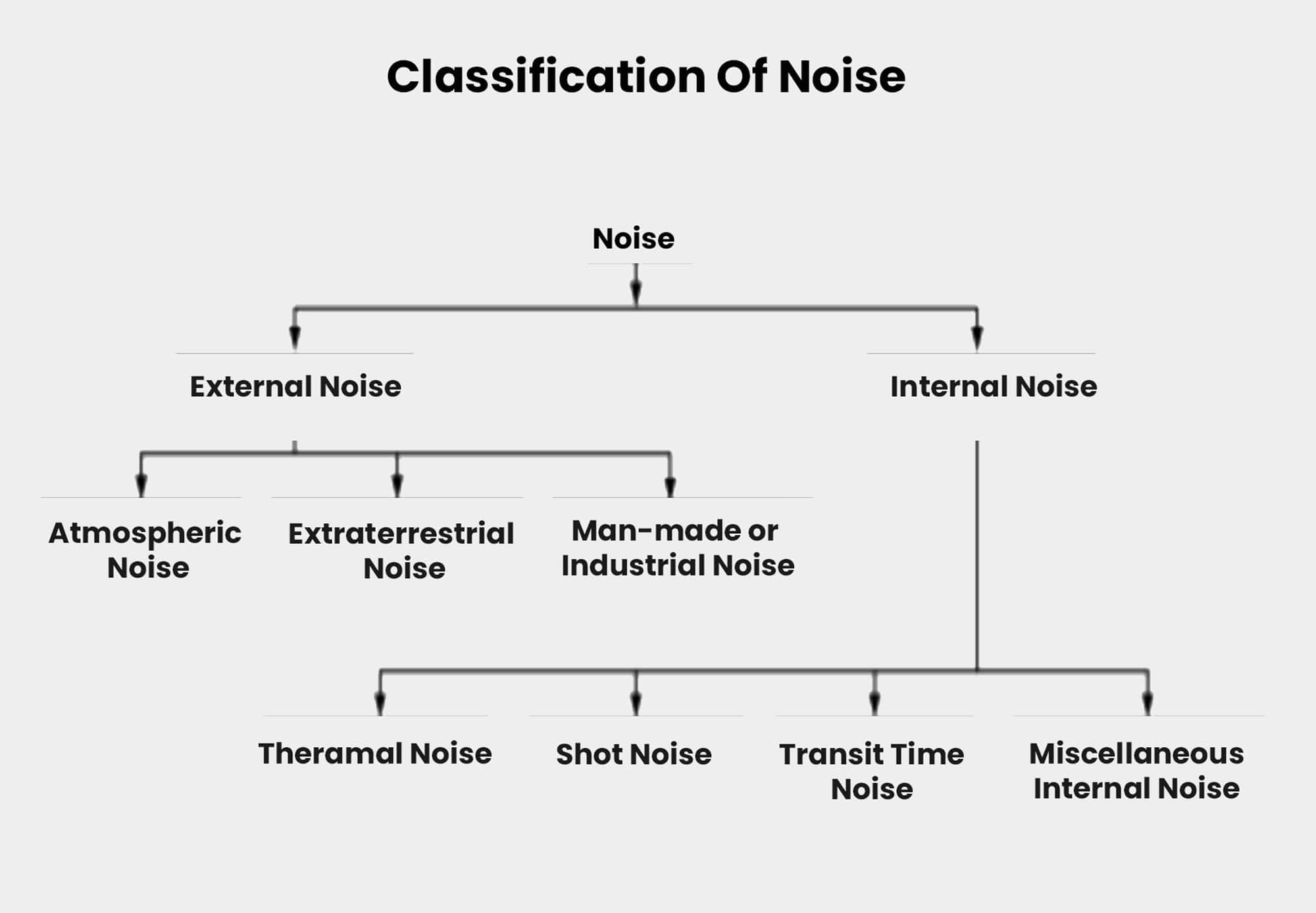
There are two sources of noise that affect SNR: external and internal.
External source
External source noise is either natural or man made. Common examples include:
- Atmospheric noise from irregularities in the atmosphere, like lightning discharges in thunderstorms.
- Extra-terrestrial noise, like solar noise and cosmic noise.
- Industrial noise.
This is the worst kind of SNR because you can’t completely eliminate it — but you can manage it. The best way of doing this is to avoid the noise affecting the speech signal in the first place.
Internal source
Internal source noise is caused by the receiver components during functioning. Common examples are:
- Thermal agitation noise, like Johnson noise or Electrical noise.
- Shot noise from the random movement of electrons and holes.
- Transit-time noise during transition.
- Miscellaneous noise, like flickers, resistance effect, and mixer-generated noise.
Internal source noise can be quantified. A proper receiver design may reduce its impact.
What is the industry standard?
Conventional speech recognizers are much more sensitive than human listeners. The certain SNR value for speech depends on the application. In addition, the type of noise is also relevant. For example, competing background talking or babble is the most disruptive because it matches the spectral distribution (and modulation dynamics) of the target speech.
A useful point of reference for the range in SNR is from about 30dB (barely audible noise) up to almost -5dB (noise overwhelms the original clean signal). However, the relative difference between whispering and moderate speech is >20 dB and increased word error rates are typically seen at 20dB SNR.
A SNR of >30dB is considered clean speech. Listeners will barely notice anything better than 20dB, and intelligibility is still pretty good at 0dB SNR (this is where speech energy and noise energy are the same).
How can SNR impact the accuracy of your speech recognition?
A low level of SNR will decrease how accurately your system can recognize speech. You’ll want a robust SNR in adversely noisy conditions so that the automatic speech recognizer can also be used in real-life situations, like in a multi-person meeting.
Noise limits the systems’ operating range
Noise places a limit on the weakest signal that can be amplified. It does so indirectly and in the following way: the oscillator in the mixer circuit may limit its frequency due to noise, and because a system’s operation depends on the operation of its circuits, the noise limits the smallest signal that a receiver is capable of processing.
Noise affects the receivers’ sensitivity
There’s a sensitive balance between the minimum amount of input signal necessary and the specified quality output. If noise will affect the sensitivity of a receiver system, it will also eventually affect the output.
How to deal with SNR early on so it doesn’t come back to bite you?
It’s really important to measure the SNR early during the development process, because if you discover later on that it’s high in your audio samples then you can’t blame the problem on the speech-to-text vendor. Here are two ways you can manage this:
Signal Compensation
One way to deal with this early on in the process is by way of Signal Compensation, which means removing or reducing noise effects in the preprocessing stage (i.e. prior to feature extraction and the recognition process).
The goal is to transform the noisy signal to resemble clean speech and improve the speech signal quality. You do this with speech enhancement methods, which are used as a front end for the speech recognizer.
Spectral subtraction (SS), Wiener filtering, and model-based speech enhancement, are widely used instances of this approach. SS is simple and easy to implement. Despite its low computational cost, it’s very effective where the noise corrupting the signal is additive and varies slowly with time. This paper explores speech enhancement by spectral subtraction and with Wiener filtering, both of which appear to work well in situations where there is additive, stationary noise, commonly referred to as white noise (broadband noise, like tape hiss), colored noise, and different types of narrowband noises.
Noise Injection Theory, or noisy training
Another option you can use to tackle this issue, once identified, is a noisy training approach. By intentionally and randomly injecting moderate noises into the training data, more generalizable deep neural network (DNN) models can be learned.
Noisy training for DNNs requires samples of noise signals from some real-world recordings, which you then mix with the original training data. This can also be referred to as “noise injection” or “noise corruption.” You can use this noise-corrupted speech data as part of the usual DNNs training.
There are two benefits to this approach: Firstly, the noise patterns within the introduced noise signals can be learned and therefore compensated for in the inference phase; and secondly, the disturbance introduced by the injected noise can improve the general capability of the resulting DNN.
What to prioritize when looking for an API platform provider
So, we now know that you need a robust speech recognition system, and one that can handle a higher SNR is going to be up there with the best. When looking for a provider, be sure to make this feature a priority when assessing your options.
Symbl.ai provides a robust API. Learn more about what Symbl.ai can offer here.
Additional reading
For a deeper dive into the topics raised above, the below links are full of good detail:
- Study of different types of noise and its effects in communication systems
- How is the SNR of a speech example defined?
- Estimation of Noise Spectrum and its Application to SNR-Estimation and Speech Enhancement
- Noisy training for deep neural networks in speech recognition
- Likelihood-maximizing-based multiband spectral subtraction for robust speech recognition