
Speech to text accuracy in real-time transcription leaves a lot to be desired. But integrating your application with the right APIs and setting yourself up for success – capturing clear audio, using lossless audio formats and using technique like speaker diarization (or better yet, separate channels) – can significantly improve it.
Real-time transcription (and transcription in general) can be filled with moments like this where you see something appear in closed captions like, “I’m not sure what we can do about the muffin. It’s been sitting in the sink all day.”
You have no idea who was trying to say what, but you know it had nothing to do with muffins or sinks.
Sure, these moments can be humorous, but they’re not helpful. They are an unfortunate by-product of transcription, especially real-time transcription.
Even the most accurate transcription setup is going to capture some nonsense simply because human-to-human (H2H) conversations can be hard to follow. We have accents, we talk over each other, we have voices that sound the same, we use words that either the transcriptionist doesn’t recognize or, if you’re using AI-assisted transcription, that the AI doesn’t know.
How to improve real-time speech to text accuracy
Unlike batch transcription, which is done after the fact and at a much slower pace, real-time transcription requires a keen ear, attention to detail, and the ability to focus on sometimes complex conversations without distraction (which is why real-time transcription can be expensive).
The good news is that transcription with enhanced AI can help. Not only is it more accurate, but it’s getting increasingly cheaper, although it’s still not perfect.
AI can help you improve the accuracy of real-time transcription when combined with factors like clear audio, sentence boundary detection, punctuation detection and speaker diarization.
Ensure clear audio
This is the best thing that you can do to improve the speech to text accuracy of your real-time transcription – and it’s also one of the things that you have the least amount of control over.
Clear audio is best because there’s less noise happening on the feed. This means there isn’t a lot of background noise, each speaker is coming in loud and clear, and the audio is being captured in a format that is usable.
Ideally, each person would have his/her own microphone (preferably wired) and the conversation would be happening in a space that minimizes background noise (e.g. a meeting room).
The challenge here is that, unless the audio is being captured in a studio setting that you can completely control, it can be hard to get a perfectly clear recording for everyone. Poor connectivity also impacts the accuracy of the transcription, but it’s tricky to guarantee a stable, high-bandwidth network connection for each participant.
Use speaker diarization
Speaker diarization is the process of sectioning an audio stream that contains multiple speakers into segments that are associated with each individual speaker. In other words, it blocks off chunks of audio based on who’s speaking at the time. This makes it easier for the AI to identify who each person is, when they’re talking, and what they’re saying.
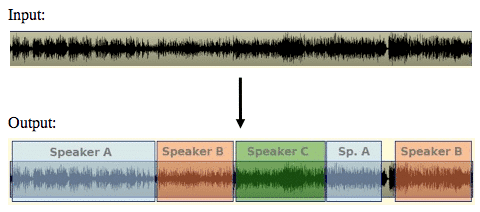
Figure 1 – Speaker diarization creates segments for each speaker identified in a conversation (Source)
Speaker diarization doesn’t necessarily improve word error rate, but you do get better context for the conversation (which improves accuracy) and you’re able to better establish who said what during the conversation.
Speaker diarization typically follows a process like this:
- Speech detection: This phase uses a Voice Activity Detection tool to identify which sections of the audio are speech and which sections aren’t. This allows the system to trim out things like silence and any sounds that aren’t obviously speech.
- Speech Segmentation: Speech segments are extracted in small chunks, typically broken up by words, syllables, or phonemes (the smallest unit of sound within a word). These segments are pulled out one speaker at a time.
- Embedding extraction: A neural network-based embedding of the segments is created as a vector representation of the data.
- Clustering: The segments are then clustered together and labeled based on who’s talking. This helps identify who’s talking at any given time and also identifies the number of participants in the conversation.
- Transcription: The final stage where the spoken conversation is converted into text.
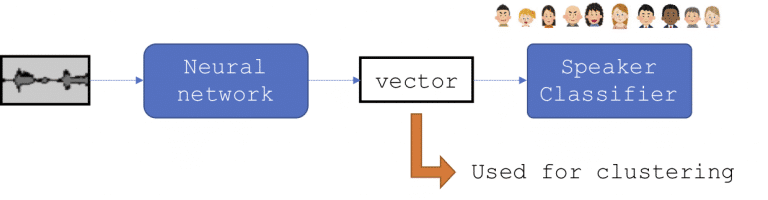
Figure 2: A simplified version of the diarization process
Use separate channels
Another factor that may be out of your control but ultimately leads to better transcriptions is to capture each speaker in their own audio channel. What this does is provide a separate, clear audio channel for each person. It is, in a sense, a hardwired version of speaker diarization.
Use lossless audio formats
When capturing audio, even for real-time transcription, you need to make sure the audio stream is high quality. When audio is compressed into different formats you lose quality, meaning some sounds get muddled or lost completely. A lossless format, like FLAC or WAV, doesn’t compress the audio and, as a result, preserves the integrity of your audio.
Custom vocabulary
Most industries use words that are specific to their industry. These words can be challenging during real-time transcription because they’re either words that don’t exist outside of the industry (things like acronyms) or they’re commonly used words that have industry-specific meaning.
With AI-assisted transcription, you can train the AI to recognize and understand those custom words to help the system provide more accurate transcriptions.
Get better transcriptions using conversation intelligence
It might sound like there’s a lot of work involved in improving the accuracy of real-time transcription, but a lot of these features (not the ones that require control over the recording location) can be easily added via Symbl.ai APIs.
In fact, Symbl.ai has built the context-aware conversation intelligence platform that enables you to to use context to enable accurate real-time transcription. Our streaming API lets you capture conversations in real-time and you can easily add speaker diarization functionality, as well as custom vocabulary, to ensure that you get the most accurate transcriptions possible. And, our advanced contextual AI that understands the various dimensions of the conversation and uses it to further improve the recognition of the text and who said what – so you get the most accurate transcriptions and relevant insights possible.
Want to know more? Check out our documentation to learn how you can get started with our easy-to-use APIs.
Additional reading
What’s That, Human? The Challenges of Capturing Human to Human Conversations