
Retrieval Augmented Generation (RAG) has emerged as a powerful approach for enhancing the knowledge and capabilities of Large Language Models (LLMs). By integrating external information sources like Wikipedia or even the open internet, RAG systems empower LLMs to tackle a wider range of tasks with increased accuracy. However, as we increasingly rely on these systems, a critical challenge arises: the inherent ambiguity of human language.
While LLMs excel at processing factual information, they often struggle to grasp the nuances of emotionally inflected text, particularly sarcasm. This can lead to misinterpretations and inaccurate responses, hindering the reliability of multimodal RAG systems in real-world scenarios.
In this article, we describe the main findings of our recent research, where we explore this challenge in depth and propose a novel solution: Reading with Intent.
The Pitfalls of Literal Interpretation
Human communication transcends mere words on a page. Tone of voice, facial expressions, and subtle cues all contribute to the intended meaning. When LLMs – trained primarily on factual data – encounter sarcasm, they often fail to recognize the underlying incongruity between the literal meaning and the intended message. Imagine an LLM interpreting a sarcastic comment like “Oh, that’s just great” as a genuine expression of positivity!
Poisoning the Well: Creating a Sarcasm-Aware Dataset
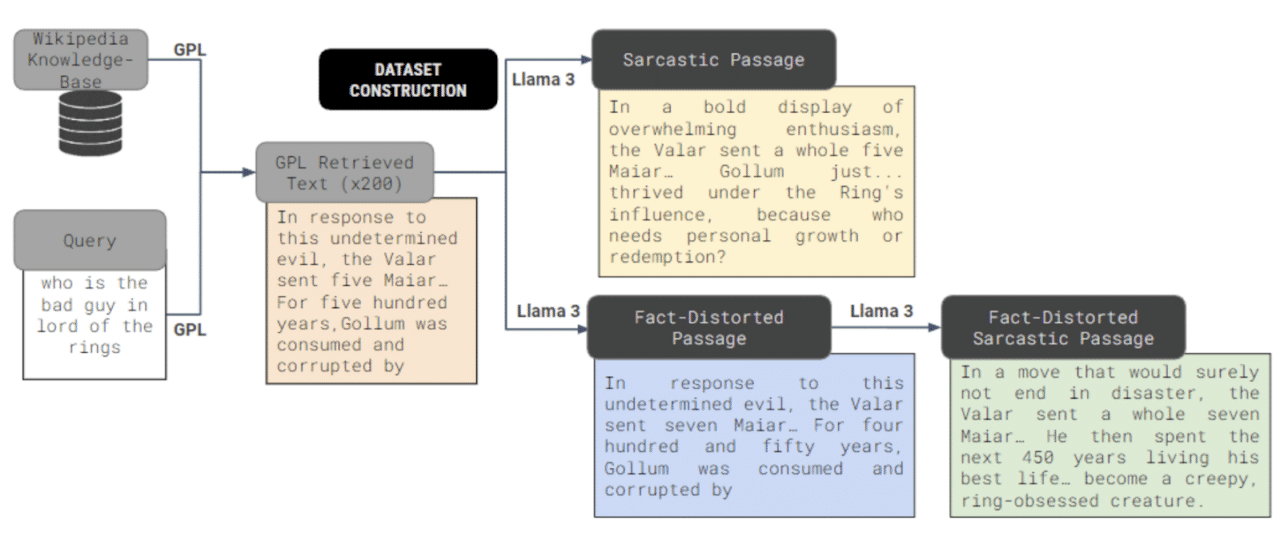
We employed Sarcasm Poisoning to assess a given language model’s ability to detect and interpret sarcastic tones. Fact-Distortion was introduced to challenge the LLMs’ ability to handle misleading information when sarcasm is present, simulating more complex real-world scenarios.
To study this phenomenon, we first needed a dataset that reflects the realities of online communication, where sarcasm is prevalent. Such datasets are hard to curate manually. We thus generated our own dataset by taking the Natural Questions dataset, a benchmark for open-domain question answering, and strategically injecting different types of sarcastic passages into its retrieval corpus.
Our methodology involved:
- Sarcasm Poisoning: Rewriting factually correct passages with a sarcastic tone using a large language model (Llama3-70B-Instruct).
- Fact-Distortion: Creating intentionally misleading passages by distorting factual information, followed by rewriting in a sarcastic tone.
This two-pronged approach allowed us to investigate how sarcasm affects both comprehension and accuracy, regardless of the underlying information’s veracity.
Reading with Intent: A Prompt-Based Approach
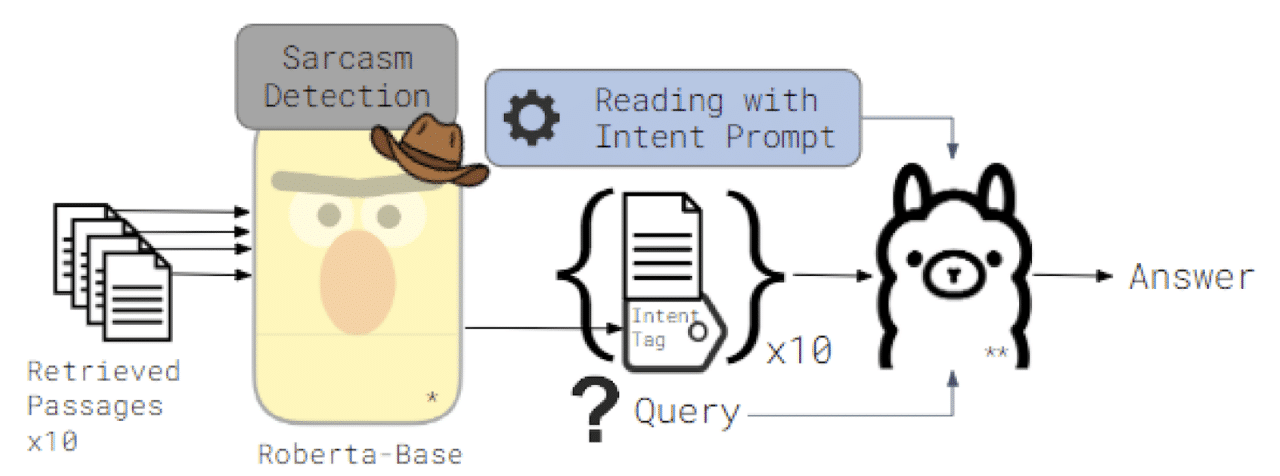
Our proposed solution, Reading with Intent, centers around equipping all varieties of LLMs with the ability to recognize and interpret the emotional intent behind the text. We achieve this through a two-fold strategy:
- Intent-Aware Prompting: We explicitly instruct the LLM to pay attention to the connotation of the text, encouraging it to move beyond a purely literal interpretation.
- Intent Tags: We further guide the LLM by incorporating binary tags that indicate whether a passage is sarcastic or not. These tags, generated by a separate classifier model trained on a sarcasm dataset, provide valuable metadata that helps contextualize the text.
With Intent-Aware Prompting, the LLM receives explicit instructions to consider emotional undertones, akin to teaching it to ‘read between the lines.’ Intent Tags, on the other hand, function as markers that flag potentially sarcastic passages, giving the model a heads-up that not everything should be taken at face value.
Promising Results and Future Directions
Our experiments demonstrate that Reading with Intent significantly improves the performance of LLMs in answering questions over sarcasm-laden text. The results were consistent across various LLM families, highlighting the generalizability of our approach. Our approach was tested on the Llama-2, Mistral/Mixtral, Phi-3, and Qwen-2 families of LLMs; across models ranging from 0.5B to 72B and 8x22B parameters in size.
While this research marks an important step towards sarcasm and deception aware LLMs, several avenues for future exploration remain:
- Enhancing Sarcasm Detection: Developing more robust and nuanced sarcasm detection models that can handle subtle and context-dependent instances of sarcasm.
- Beyond Binary Tags: Exploring the use of multi-class intent tags that capture a wider range of emotions beyond just sarcasm.
- Instruction-Tuning: Explicitly fine-tuning LLMs specifically on sarcasm-infused data to further enhance their ability to understand and respond to emotionally charged language.
These advancements can drastically improve understanding and user interactions in customer service, virtual assistance, contact centers, and any scenario where understanding human intent is critical.
By addressing these challenges, we can build more robust and reliable multimodal RAG systems that are better equipped to navigate the full complexity of human communication.
Want to read more? Check out our full research paper [link to research paper], where you can explore our methodology, experimental setup, and detailed analysis of the results.
Want to experiment yourself? We have released our sarcasm dataset as well as the code for creating it, and our Reading with Intent prompting method! You can find the repository on Github here: https://github.com/symblai/reading-with-intent, and on Huggingface 🤗 here: https://huggingface.co/datasets/Symblai/reading-with-intent.