White Paper — Elevating Automatic Speech Recognition to the Next Level with Unified Modeling
Introduction
Automatic Speech Recognition (ASR) or Speech-to-Text (STT) is a technology that converts spoken words into text. This technology is becoming increasingly important in a world that relies on voice-based interfaces for communication. ASR is a crucial part of any communication system in which users converse and interact. ASR outputs no longer simply serve the purpose of recording and generating conversation transcripts for businesses. It is used as an input to further downstream AI systems to perform more sophisticated tasks. This requires high accuracy and reliability of ASR to reduce the noise in further systems. With the evolution of use cases, it is becoming even more critical to have better accuracy and reliability of ASR systems in a wide range of business use cases. These include Sales Coaching, to provide high visibility in agent performance and real-time and offline coaching; Call Tracking, to track the progress of the call in the contact center and for assisting agents; and Automatic Note Taking, to take notes in meetings automatically. Long audio transcriptions in async mode from recorded files and real-time mode from live audio streams have become necessary to unlock value from human conversations across many business use cases.
There are various tasks a complete ASR system needs to perform, such as: acoustic modeling, audio denoising, language modeling, punctuation, sentence boundary detection, inverse text normalization, and others. Traditionally, the legacy ASR system approaches have one or more separate components for each task. These approaches no longer hold the advantage of modularity with the limitations in the performance they can achieve. Modern techniques use Deep Neural Networks (DNN) for baseline speech recognition modeling. However, most of them only focus on acoustic and basic language modeling parts, which is not truly the End-to-End DNN in practice. This solves important problems of legacy approaches, such as contextual prediction of words ASR produces. However, this doesn’t utilize the power of DNNs to improve the overall performance of the ASR system across all the tasks. And many of these approaches don’t work well in Streaming inferencing to power use cases that need accurate real-time ASR.
This white paper discusses the current state of the ASR technology landscape, limitations, and improvements to expand the scope of DNNs with more tasks that lead to significant performance improvements in offline and streaming ASR inferencing.
This white paper also introduces Symbl.ai’s breakthrough Unified Modeling approach to ASR, which uses a single unified deep neural network architecture to handle the entire transcription processing pipeline – as depicted in the diagram below:

Current Approaches
Let’s discuss the most recent ASR system design and build approaches and their evolutions, starting with legacy systems.
The logical improvements in ASR system design are categorized below –
- Legacy design – Multiple components where one or more components are responsible for one step in the processing pipeline of the ASR system.
- End-to-end DNN for Acoustic and Language Modeling, isolated components for the rest of the processing.
- End-to-end DNN for all the involved tasks.
There are two types of ASR system approaches at a broader level to understand the working mechanism of the ASR system – legacy systems and end-to-end deep learning systems. Any ASR system aims to produce readable, well-formatted text from a given audio. The ASR system systematically configures one more component: algorithms, classical models, or deep neural network models.
Any typical ASR system needs to take care of certain tasks as part of its processing, including:
- Preprocessing of Audio: Remove any noises, enhance human speech frequencies in the signal, and convert the audio signal from the time domain to the frequency domain to improve the signal quality for better acoustic modeling in speech recognition.
- Acoustic Modeling: Extract features from the audio signal and encode them as a machine-learning model. This part is responsible for “learning” the audio features of the audio signal, which can be used further for converting them to phonemes, words, or sentences.
- Phonetic Modeling: Convert the encoded audio from the acoustic model to phonemes representation. Phonemes are distinct units of sound representing how a certain speech sounds in the form of characters.
- Language Modeling: Model the understanding of spoken language. The language model takes a phonetic or encoded audio signal and converts that to a word based on the contextual relevance of the understanding of language.
- Sentence formation: Identify and enhance text from the language model to create proper sentence boundaries and add correct punctuation. If the language model cannot model semantic understanding of sentences in the context of the dialogue, this part is typically a separate component.
- Entity Formatting: Identify entities in the raw text and convert them to the required formats, also known as inverse text normalization. This involves:
- Convert cardinal entities, such as numbers, currency, date, time, phone numbers, account ID, credit card numbers, etc., to their natural format.
- Capital casing for proper nouns such as names of people, companies, locations, etc.
- Casing and formatting of abbreviations
- Formatting of complex entities such as an address, email address, etc.
- Custom or post-processing operations: Any additional post-processing operations. For example – redacting profane of PII parts of the output.

A full-fledged commercial ASR system can have more tasks complementing the baseline ASR tasks above, but for the scope and relevance of this paper, we will focus only on baseline tasks.
Now let’s understand the various current approaches to ASR systems used in the industry in more detail.
Legacy ASR Systems and Limitations
When we refer to legacy ASR systems, we refer to systems built before the advancements in deep neural networks in modeling basic ASR components – acoustic model and language model.
Legacy systems have one or more components for each step in the process. They are typically sequentially arranged to pass on the output of one component to another, where the final component produces the final transcription output. Older techniques, such as Hidden Markov Modeling (HMM), n-gram language models, state machines, dependency parsing algorithms, etc., are used to build these components. Separate neural networks are sometimes used in conjunction. However, the scope of each component is isolated, and these components cannot learn from each other, as they are trained in isolation.

Limitation of Legacy Systems
- Legacy systems are not robust learners; in other words, they cannot learn complex patterns with limited data. These systems have many completely isolated components arranged sequentially. This design inherently loses information at each step from the previous step. There’s no coupling between components further in the sequence to provide feedback to previous components. Because of these reasons, the components do not learn about their mistakes in each step. This makes the system very lossy, with no way to improve further but to increase the amount of data.
- The sequential nature of the legacy systems leads to error propagation from one component to the other. It can produce significantly worse outcomes on out-of-distribution input audio in certain cases. As the diversity of the data increases, keeping the error rate under control becomes very challenging.
- As a result of the previous two factors, these systems require huge data to yield realistically acceptable accuracy. This increase in data while maintaining the diversity in data also requires improvements in the model architecture to maintain the performance. This leads to a set of very bulky models. It adds to the time and resources required to maintain and host the system and becomes expensive.
- More components lead to more maintenance overhead. Each model needs to be trained, tested, optimized, and maintained separately on an ongoing basis. Enhancing and extending the functionality of the system becomes complicated.
- Following the above point, the system’s complexity makes it less suitable for real-time inferencing. A separate set of models must be trained and maintained, optimized for real-time inferencing in lower latency. Maintaining accuracy with increasing model sizes of multiple models for streaming becomes costly and hard to maintain.
Deep Learning ASR Systems
There are two variations based on the coverage of DNNs in the ASR system:
- DNN for Acoustic modeling only, language modeling, with the rest of the tasks not being part of the DNN model and are separate components on their own, like legacy systems (CTC).
- DNN for Acoustic and Language modeling and the rest of the tasks are separate components.
DNN-based Acoustic Modeling
By utilizing one of the popular DNN architectures suitable for acoustic modeling, the acoustic modeling part is handled by a single deep neural network. This improves acoustic modeling performance and simplifies acoustic modeling more than legacy systems by combining pronunciation and baseline acoustic modeling in a single DNN. However, the rest of the parts of the ASR system are still mostly legacy and inherit the limitations in those areas – language modeling, sentence formation, and entity formatting-related tasks.
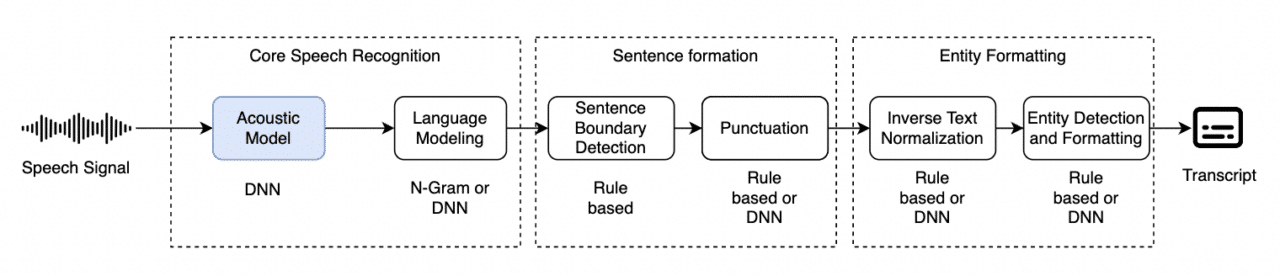
Limitations
- Acoustic modeling being separate from Language modeling, makes this system learn speech, language, sentences, and entities separately. Because of this, the system cannot learn contextually about language and how to represent it better and more appropriately.
- This issue is even more significant if the independent language model is n-gram based. The system will not have a good context of language and can easily transcribe non-sensical sentences such as –
- expected: “I want to buy the latest iPhone.”
- transcribed: “I want to try the latest eye bone.”
- With a DNN based language model, such issues about language sensibility can be addressed; however, the system struggles with associating vocal and speech attributes to language, punctuation, sentence construction, and entity contexts. As a result, it struggles with correctly transcribing based on pauses, emphasis, tone, noise, and several acoustic features in correlation with language consistency.
- This issue is even more significant if the independent language model is n-gram based. The system will not have a good context of language and can easily transcribe non-sensical sentences such as –
- Due to the inability to learn contextually, the system needs a huge amount of data to make a relatively minor impact on performance. It makes this system expensive and adds quite a lot of maintenance overhead.
- The system suffers from error propagation issues as most pipeline components are independent and cannot learn from each other.
DNN based Acoustic and Language Modeling
Acoustic modeling and language modeling are both done through a DNN model. This allows the model to learn the language features, use words more robustly, and solve the language contextuality problem. However, the rest of the parts of the system are isolated components and are pretty much the same as the legacy systems.
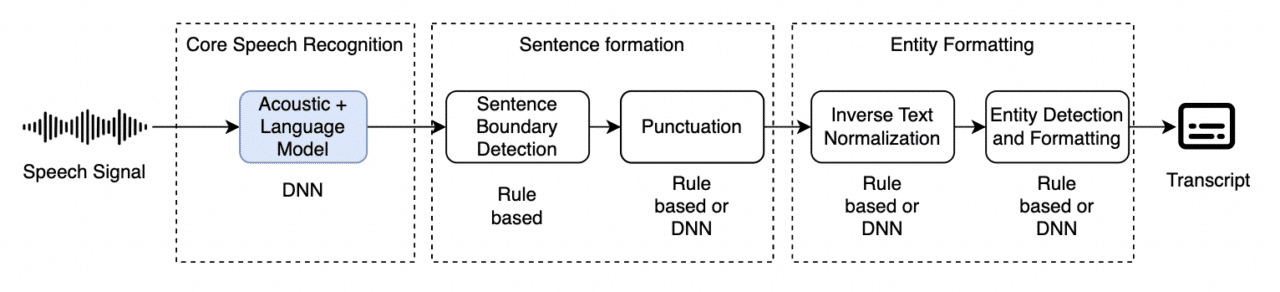
Limitations
- Although the language context problem is addressed in this system, the rest of the components responsible for sentence formation and entity formatting are isolated. The system cannot learn contextual sentence formation and entity formatting on top of speech and language features.
- The lack of contextual learning on sentence formation and entity formatting leads to lower performance in the system on downstream tasks such as, sentence boundary detection, punctuation, inverse text normalization, entity detection, and formatting tasks.
- Typically, a single network for the acoustic and language model architecture makes the system more compute-intensive and creates bottlenecks in streaming performance.
- Due to the direct mapping of acoustic and language modeling networks, the overall system suffers from precision issues relative to timestamps and word predictions.
- The system still suffers from error propagation issues in downstream tasks, as the components cannot learn along with each other.
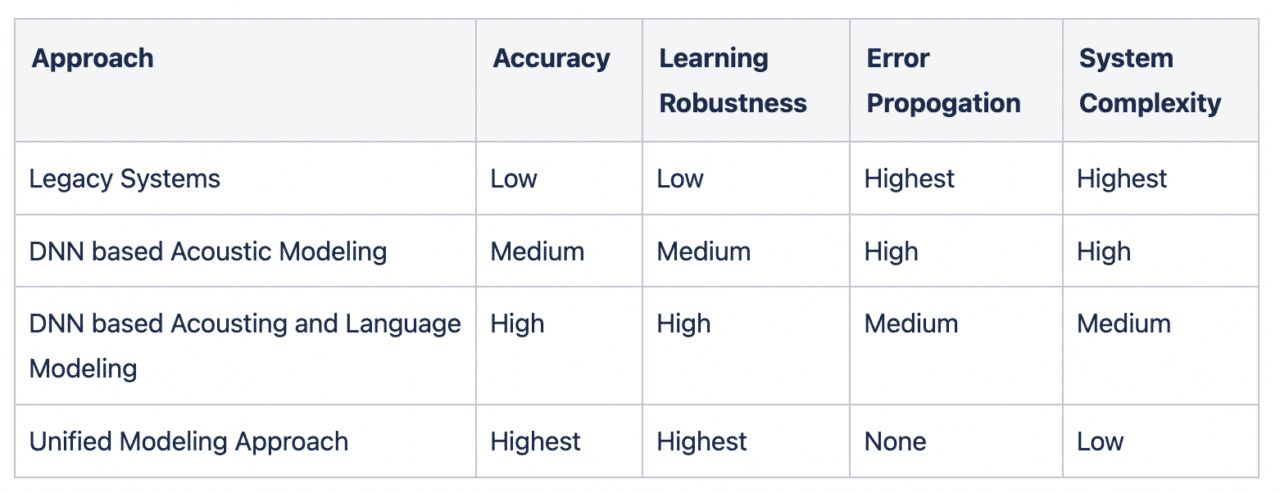
Comparison summary
Introducing the Unified Modeling Approach
Current approaches have either isolated components that lead to inefficient systems and high error rates, or have a limited portion of the ASR processing done in DNN. These systems cannot learn to model the relationships between various entities and punctuation within the context of the dialogue segment. Even when the language and acoustic networks are combined, the system either becomes unoptimized for streaming inferencing or reduces its timestamp precision, or both. For example, let’s consider a simple interaction below; with the above approaches, the DNN would produce something like this:
“i have processed your order you will receive your order on thirty first january and you will be charged eighty two seventy five in total eighty two seventy five yes”
The DNN model produces the text in lowercase normalized form because the model has learned only the basic task of converting audio into a sequence of words but has not learned how to punctuate it or understand various entities and represent them in the right form. To address this, additional components will be required to perform the tasks of punctuation, inverse text normalization, entity casing, etc., separately.
To address the design limitations of the legacy and deep learning approaches discussed in the previous section, we use a single unified deep neural network architecture to model tasks beyond just baseline acoustic and language modeling, such as punctuations, sentence boundary detection, inverse text normalization, entity detection, and formatting. We also employ a transduction-based architecture for joining various models to work as a unified large deep neural network in training and inferencing. This also makes the same system work in both asynchronous and streaming modes without compromising model accuracy.
Take the same example above; with this approach, the DNN model will produce the following:
Agent: I have processed your order. You will receive your order on 31st January. And you will be charged $82.75 in total.
Customer: $82.75?
Agent: Yes.
Here we can see that the model produces all entities formatted in the expected form with proper punctuation and without any additional components needed. We also see that the model understands the context of the dialogue and uses that to format entities and punctuation. For example, for the entity “$82.75,” the currency part was never uttered explicitly but is implicitly understood. The model understands that there’s a number in the context of payment from charging for an order. It, on its own, fills the gap to represent it as a currency value. Similarly, in “$82.75?” the question mark is inferred by the model based on the tone of the speech used while uttering the number by a different speaker and has been repeated right after uttered by the other speaker. Our model significantly elevates this contextual learning at the language and speech levels.
The new Symbl.ai approach handles the entire processing pipeline with a single unified DNN. This allows the model to learn more complex relationships beyond the basic sequence of words from the spoken language in the context of the dialogue and the audio features. Since the single model is learning the use of various entities like currency, address, names of people, date, time, etc., along with the audio encoding network and language modeling network, it not only learns to detect these complex entities and format them directly in the same neural network, but it also learns the contextual use of them. This also addresses the precision issues related to timestamps and word prediction by delegating the responsibility of learning precision timestamp prediction to another neural network as part of the same deep neural network architecture.
Model Training
There are several techniques for training speech recognition models. Training is the phase of building a model when it learns to understand the audio and convert it to expected text output. Depending on the system, either the training is done in isolation for each DNN or together. For example, in the highly isolated designs of legacy systems, all models would be trained separately, whereas for combined tasks in DNN, two or more DNNs might be trained together.
There are four training methodologies used in training speech recognition models:
- Supervised Learning – The model is provided with 100% of data labeled accurately as its training data. Where the audio and its corresponding text as a labeled ground truth is provided. Humans manually label the ground truth by transcribing the audio into text. The labels are the gold standard for accuracy.
- Weak Supervised Learning – In this method, the model is provided with not necessarily very accurate labels in the data, and the labels may contain imperfections and inaccuracies. This can be combined with the accurate human-labeled ground truth. This technique’s total amount of data is usually higher than supervised learning. The model learns to avoid inaccuracies in the data, pay attention to accurate parts of data, and generalizes its learning to predict accurate text from the audio.
- Semi-Supervised Learning – The model is trained with supervised human-annotated data and unannotated data. The model is trained to generate labels for unlabeled data, and human-annotated data is used to validate its predictions.
- Self-Supervised Learning – Only audio data is provided to the model during training. The model is provided with masked-out audio data and given the training objective of learning information about audio by trying to predict the masked portion.
- Unsupervised Learning – Similar to self-supervised learning, only audio data is provided to the model during training. The model tries to identify patterns in audio data and their associations with output text with the help of unsupervised learning algorithms.
The speech recognition models are built using all of the above techniques and depend on the model type and scope of the use case.
Creating separate models for each variation, such as language, dialect, and use case is possible. However, it creates a redundancy problem in the system and suffers from overfitting problems on the variation. This means it’s not cost-effective to maintain multiple models, and the model severely suffers when applied to speech recognition on slightly different variations. For example, a specialized model of British English would suffer when exposed to Indian English, where most English language and pronunciation knowledge is common. But since the model is overfitted with British English, its utility is limited to only one accent. This can be a good idea in scenarios where the input data is not expected to deviate. Still, as the number of scenarios increases, the variations also increase, and the system can produce subpar results if all required variation models are unavailable.
Conclusion
Speech recognition technology has evolved over the years, but previous techniques suffer from several problems when building a production-ready singular architecture for practical use cases. Legacy system architectures are the most problematic, although even more recent techniques that use DNNs for Acoustic and Language modeling carry some of the flaws of legacy systems. Error propagation and lack of contextual learning at several levels of the ASR pipeline are common issues with most previous techniques.
Symbl.ai’s Unified Modeling approach solves the issues from legacy and previous techniques related to error propagation, contextual learning beyond just words, and precision issues related to timestamps, which can be a concern in some previous architectures. The Unified Modeling approach learns to model long-term relationships between audio, language, and sentence boundaries at the dialogue level and even identifies and properly formats entities mentioned in speech with a single deep neural network, producing higher-accuracy and higher-quality transcripts.
Speech recognition modeling techniques are constantly evolving, and the conversation intelligence landscape is more exciting than ever. At Symbl.ai, we’re pumped to get inspiration from them and continue to contribute our work in speech recognition and other areas toward building best-in-class AI systems to understand all aspects of human conversation.
To learn more about Symbl.ai or to schedule a product demo, contact us here.