
Choosing the right integration approach and providing speech data to a Voice or Audio API is straight-forward if you take the time to understand the complexities and plan accordingly. These guidelines help decision-makers understand key considerations so you can move forward with a strategy that works for the long term.
Choosing the right API
Here’s a quick decision flow to help you choose the right API for your business. 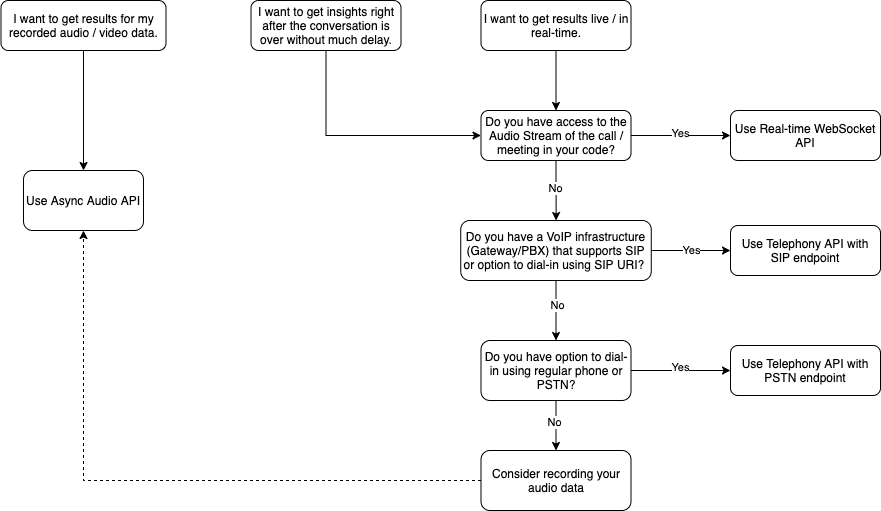
General Best Practices
After choosing the best API for your needs, the next considerations for accuracy and efficiency are:
Sampling Rate
- Capture the audio at the source with a sampling rate of 16,000 Hz or above when integrating over SIP.
- Lower sampling rates may lead to reduced accuracy
- If you cannot capture audio at the source with 16,000 Hz or higher, don’t re-sample the original audio to bump up the sample rate because this can reduce accuracy
- Retain the original sample even if it is lower than 16,000 Hz. For example, in telephony the native rate is commonly 8000 Hz.
Audio Chunk (Buffer) Size
- For live audio streaming use cases (Telephony with SIP and Real-time WebSocket API), use a single audio chunk or buffer size closer to 100-millisecond for a balanced latency vs efficiency tradeoff
- Larger chunk size in the audio is better for accuracy but will add latency
- For example:
- Buffer or chunk Size of 4096 bytes (4k) for
LINEAR16Audio where each sample is 2 byte (16-bit), at 16,000 Sample Rate, the chunk size in milliseconds would be – (1 / ((2 * 16000) / 4096)) * 1000 = 128 ms. - Whereas, if buffer size is increased to 8192 bytes (8k) for the same configuration, the chunk size in milliseconds would be – (1 / ((2 * 16000) / 8192)) * 1000 = 256 ms.
- For buffer size of 2048 bytes (2k), it would be (1 / ((2 * 16000) / 2048)) * 1000 = 64 ms.
Background Noise
- It’s best to provide audio that is as clean as possible
- Excessive background noise and echoes can reduce accuracy
- When possible, position the user close to the microphone
- If you are considering noise cancellation techniques, be aware they may result in information loss and reduced accuracy. If unsure, avoid noise cancellation.
- Don’t use Automatic Gain Control (AGC)
- Avoid audio clipping
Multiple People in a Single Channel
- Ensure audio volume for each person is the same. Differing audio levels for speakers can be misinterpreted as background noise and ignored.
- Where possible, avoid multiple speakers talking at the same time
- Push Speaker Events to indicate the start and stop times for each person in the meeting or call.
For optimal results, consider using Real-time WebSocket API with speaker separated audio.
Calibration
- Symbl provides the optional calibration phase that helps fine-tune the overall system to fit your preferences. Contact us to learn more.
Telephony API – Best Practices
SIP over PSTN
- Avoid PSTN as quickly as possible and adapt to SIP.
- In some uses cases, it can be very easy to integrate over PSTN by making a simple REST call with
phoneNumberandDTMF code. This is great for doing early experiments or PoCs, but for a production-grade deployment if possible, PSTN should be avoided. - Apart from PSTN being an expensive option when it comes to scalability, PSTN audio quality is processed with narrowband
mu-lawencoding, which is a lossy encoding and reduces the overall accuracy of the speech-to-text.
Audio Codecs
- In general, we recommend using
Opusover SIP. - Enable Forward Error Correction (FEC) with Opus in your system to optimize for accuracy, especially if your application is under poor network connection. You can also consider
AMR-WB(AMR wide-band) overOpusif that’s a feasible option. Note that,AMR-WBis patent protected, and requires the license to be used in commercial applications. - Alternatively,
Speexcan be used as a third option, but it reduces the accuracy by a small margin. - Considering the real-time nature of how audio is received over SIP possible, the use of lossless codecs
FLACorLINEAR16is not recommended in real-life applications over SIP. This should be considered only if the network reliability and robustness are very high between Symbl’s endpoint and your application. - Note that, you cannot change audio encoding for PSTN connections you can only use
mu-law.
Transmission Protocol
- Choose between TCP and UDP based transmission based on the latency vs reliability needs of your application.
- If you’re using TCP for RTP packet transmissions, the latency might be impacted by a small margin as compared to UDP based transmissions. However, if reliability is more important for your application, use TCP over UDP, especially if direct traffic is flowing from the poor network or mobile devices.
Secure SIP
- Use secure channels with SIPS and SRTP.
- Symbl supports dialing-in to insecure as well as secure SIP trunks. We recommend using secure mode in production. SIPS and SRTP are used when secure mode is enabled.
Real-time WebSocket API – Best Practices
Separate channel per Person
- Consider capturing audio for each person on a separate channel and streaming it over separate WebSocket connections for most optimal results.
- This avoids any issues caused by multiple speakers talking at the same time or different volume levels for each speaker in single-channel audio.
- If it’s not possible to capture and send audio separated by the speaker, send the mixed audio in a single WebSocket connection.
Audio Codecs
- If network bandwidth is not an issue in your application/use case, use lossless codecs –
FLACorLINEAR16to capture and transmit audio to ensure higher accuracy. - If network bandwidth is a concern in your case, consider using
Opus,AMR_WB, orSpeex. See the Audio Codecs section in Telephony Best Practices for more details.
Async Audio API – Best Practices
Audio Codecs
- Use lossless codecs –
LINEAR16, usually.wavfile containers. - The use of lossy codecs like
mp3, mp4, m4a, mu-law,etc. is discouraged as it may reduce accuracy. - If your audio is in an encoding not supported by the API, transcode it to
LINEAR16. You can consider using this opensource utility (https://github.com/symblai/symbl-media) for transcoding audio using command-line or in your NodeJS code.
You can learn about best practices for each API in our Documentation. Sign up for Symbl to get 100 minutes in free trial credits so you can put these best practices to work.